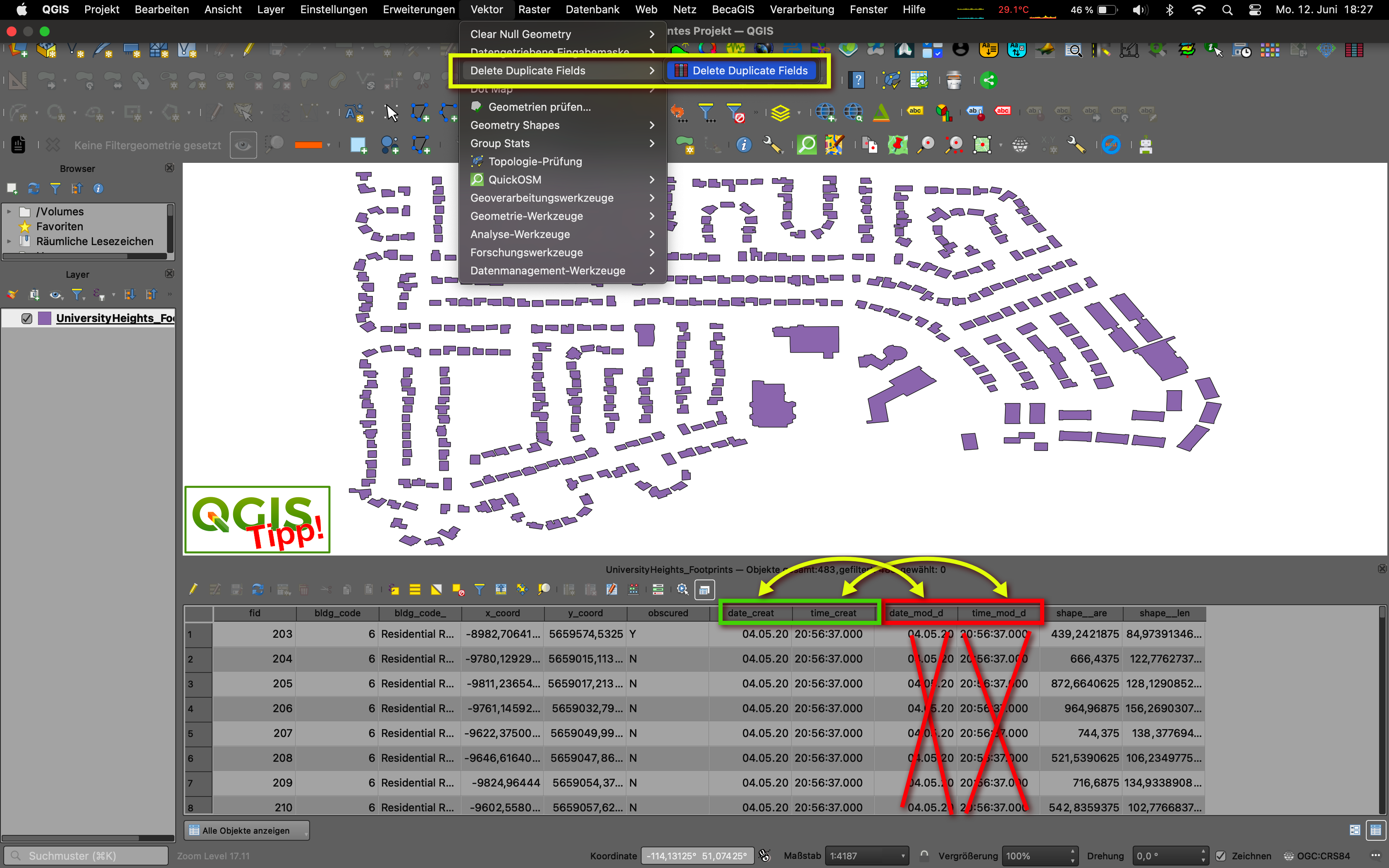
Es kommt öfter vor als man denkt, man hat oder bekommt Daten und diese haben Spalten identischen Inhalts, also vollständig redundante Spalteninhalte. Ist das Thema (der Layer) nur groß und damit unübersichtlich genug, also viele Spalten und vielen Datensätzen, wird es schwierig, die wirklichen Dopplungen zu kontrollieren. Bei 30000 Datensätzen kann man eben auf den ersten Blick nicht mehr überblicken, ob wirklich alle(!) Datensätze in Spalte A auch den gleichen Eintrag in Spalte X haben. Abhilfe schafft das neue QGIS-Plugin Delete Duplicate Fields [1]. Es identifiziert schnell und sicher Spalten gleicher Einträge über den gesamten Datenbestand eines Layers. Ich habe es mit dem Demo-Datensatz [2] und einigen eigenen Themen getestet. Es klappt und ist einfach, wirkungsvoll und verlässlich.
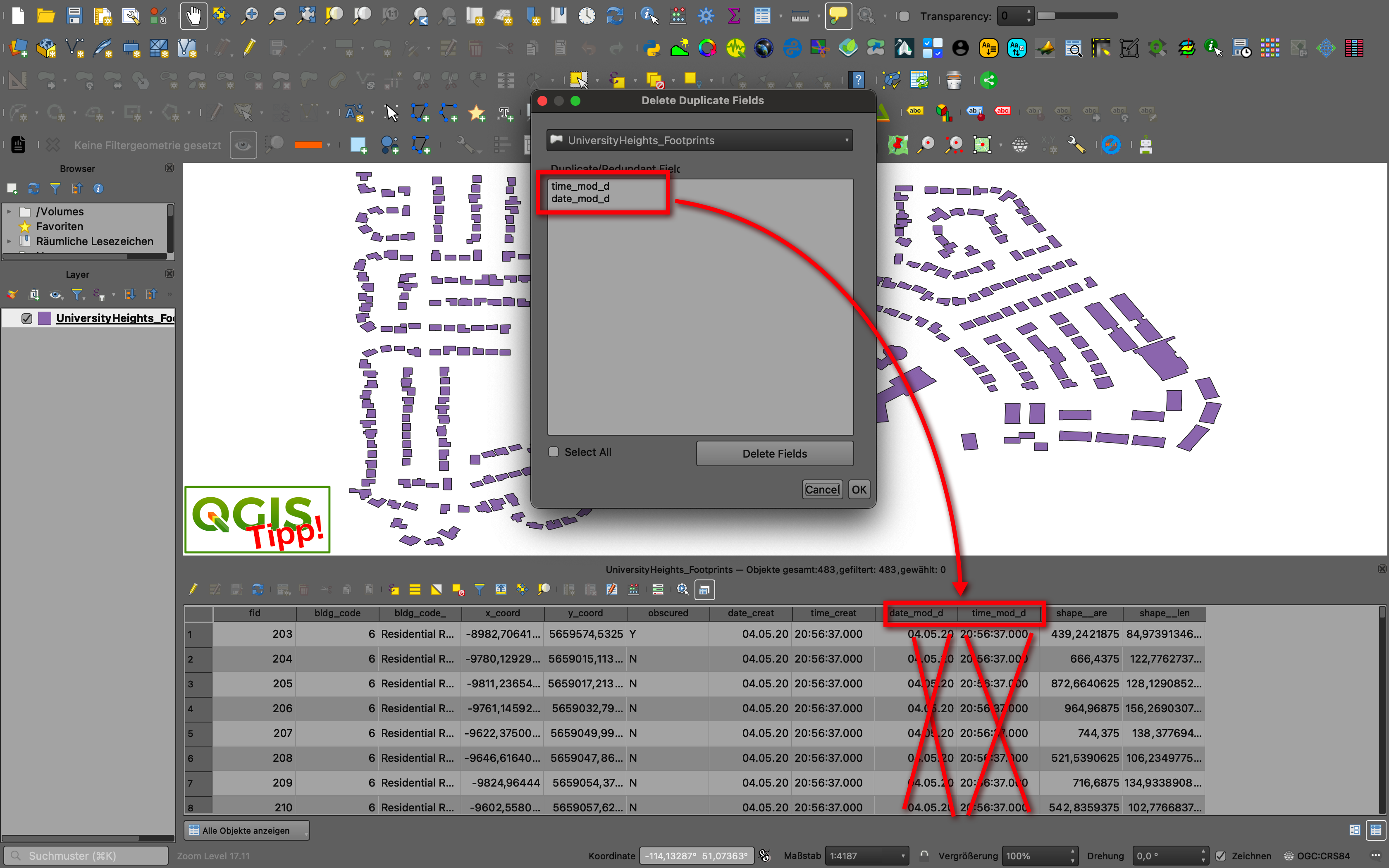
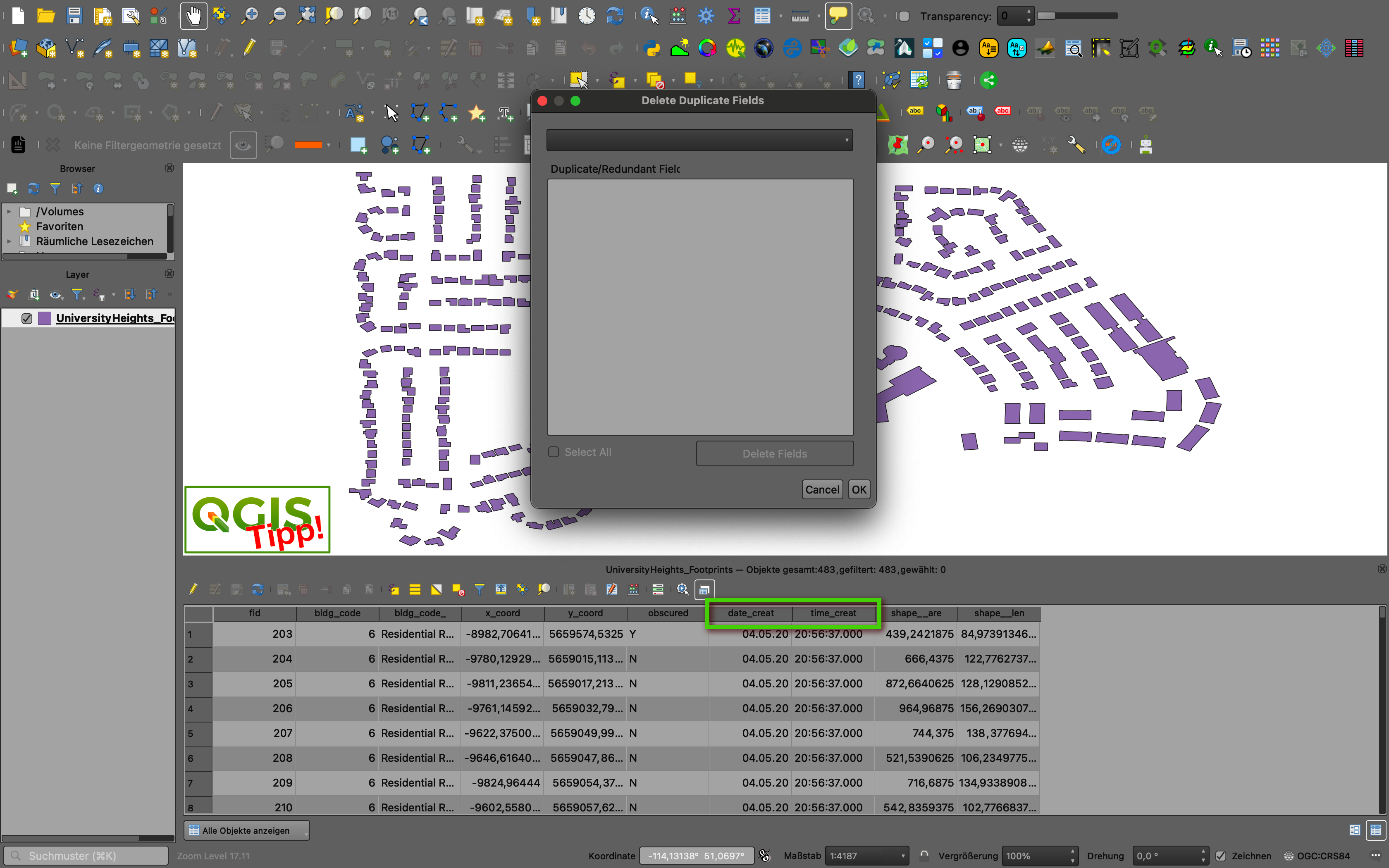
[1] … https://plugins.qgis.org/plugins/Delete_Duplicates/
[2] … https://github.com/blairscriven/QGIS_Delete_Fields/blob/main/test/University Heights_Footprints.gpkg