
Einen coolen Tipp für die Beschleunigung von DB-Abfragen in der PostgreSQL-Datenbank habe ich die Tage im Artikel „PostGIS Performance: Data Sampling“ [1], [2] von Paul Ramsey gefunden. Bei Tabellen mit sehr großen Datenmengen können die Abfragen recht lange dauern, mitunter braucht man aber nur gute Näherungen und Stichproben liefern ausreichend genaue Ergebnisse. Es kann also reichen, z. B. nur ein Prozent der Gesamtheit abzufragen und dabei ein ziemlich gutes Stichproben-Ergebnis zu bekommen, aber viel (Abfrage-)Zeit zu sparen. Es hilft das „Gesetz der großen Zahlen“ [3]. Für die PostgreSQL-DB lautet das Zauberwort:
TABLESAMPLE SYSTEM | BERNOULLI
Ich war mal neugierig, hier mein ganz einfacher Test:
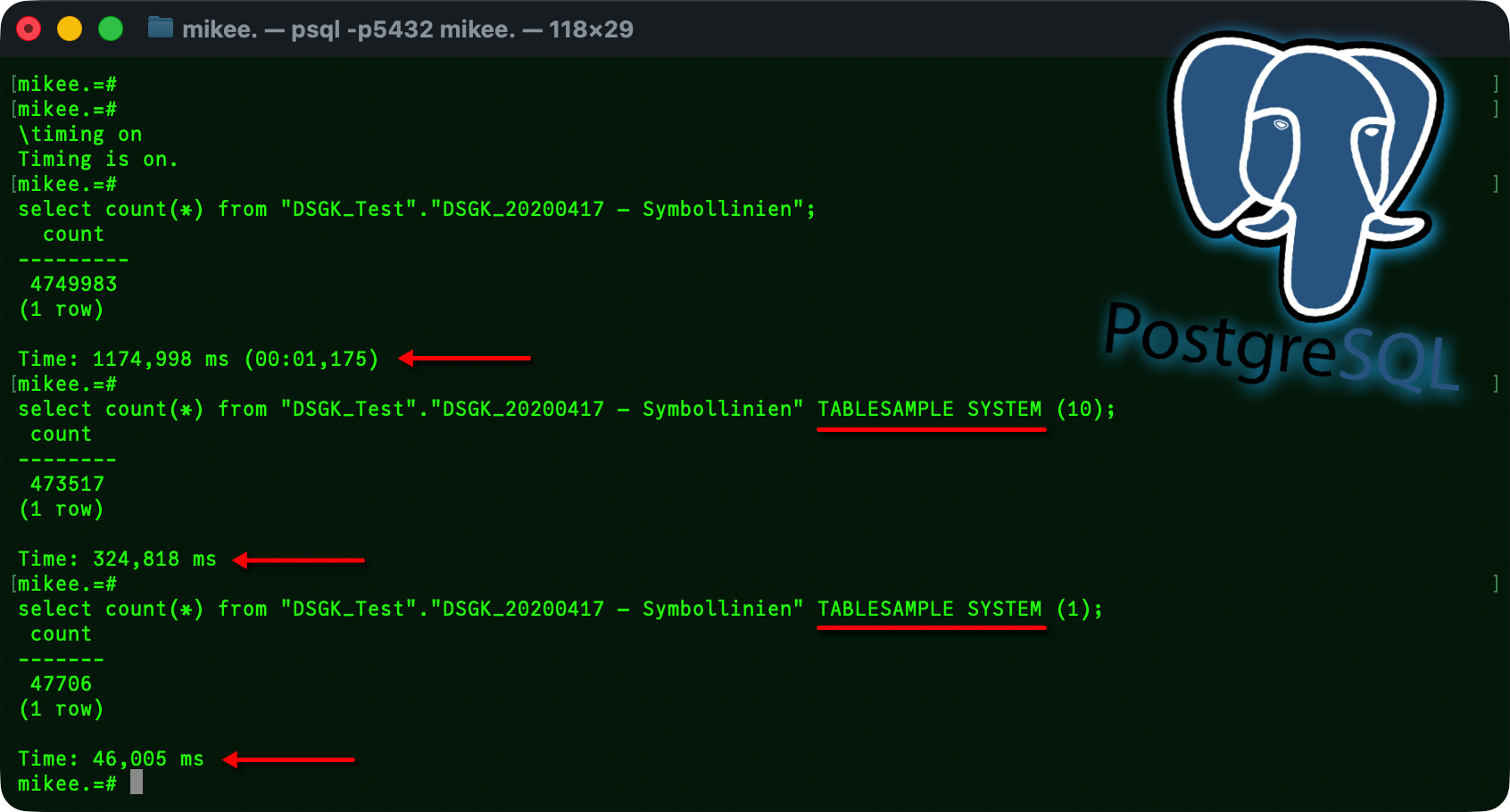
Mehr Infos inklusive dem Unterschied zwischen TABLESAMPLE SYSTEM und TABLESAMPLE BERNOULLI findet Ihr auch „How to Use Table Sampling in PostgreSQL“ bei Cybrosys [4]
[1] … https://www.crunchydata.com/blog/postgis-performance-data-sampling
[2] … https://www.linkedin.com/posts/crunchy-data-solutions-inc-_new-on-our-blog-paul-ramsey-shows-off-some-activity-7397760206929248256-8esn
[3] … https://de.wikipedia.org/wiki/Gesetz_der_gro%C3%9Fen_Zahlen
[4] … https://www.cybrosys.com/research-and-development/postgres/how-to-use-table-sampling-in-postgresql