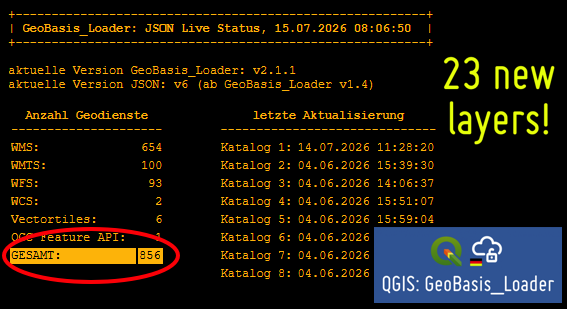
Im QGIS-Plugin „GeoBasis_Loader“ [1] sind seit der letzten Meldung einige neue Themen hinzu gekommen, z. B. die Hochwasserdaten für Sachsen, Feldblockdaten für Brandenburg und Sachsen-Anhalt und Themen des DWD. Damit sind jetzt 856 Themen verfügbar, die aktuellen Änderungen findet Ihr wie immer unter Meldungen & Störungen [2] und Status [3].
Das Hochwasser im Ahrtal ist nun genau fünf Jahre her und wir werden durch entsprechende Beiträge in der Medien wieder mal daran erinnert. Auch daran, sich mehr um die Hochwasser- und Katastrophenschutz-Problematik zu kümmern, am besten jeder in seinem Bereich, zeitnah. Der gestrige Beitrag in der ARD „Allein in der Flut“ [1] hat da was mit mir gemacht, schwer verdaulicher, sehr persönlicher Stoff, der uns auch vor Augen führt, dass vieles vermeidbar war. Und es stellt sich sofort wieder die Frage: Sind wir heute auch genügend vorbereitet?
Für mich der Anlass, gleich mal zu schauen, welche Daten zu Hochwasser-Gefährdung derzeit im Geobasis_Loader [2] verfügbar sind. Und, es sind tatsächlich nicht sehr viele. Neben den HQ200, HQ100 und HQ10 in Sachsen-Anhalt steht nur noch die Starkregenkarte zur Verfügung, eigentlich bundesweit, aber leider sind noch nicht alle Bundesländer mit ihren Daten integriert.
Und weil der Status Quo nun mal so ist, bitte ich Euch heute hiermit, falls Ihr im Open Data Sinne freie Geodienste zum Thema Hochwasser, sendet sie mir zu, ich werde sie zeitnah in den GeoBasis_Loader integrieren. Die Vorgehensweise ist unter „Mitmachen & Helfen“ [3] auf der GeoBasis_Loader-Webseite [2] beschrieben. Ich danke Euch!
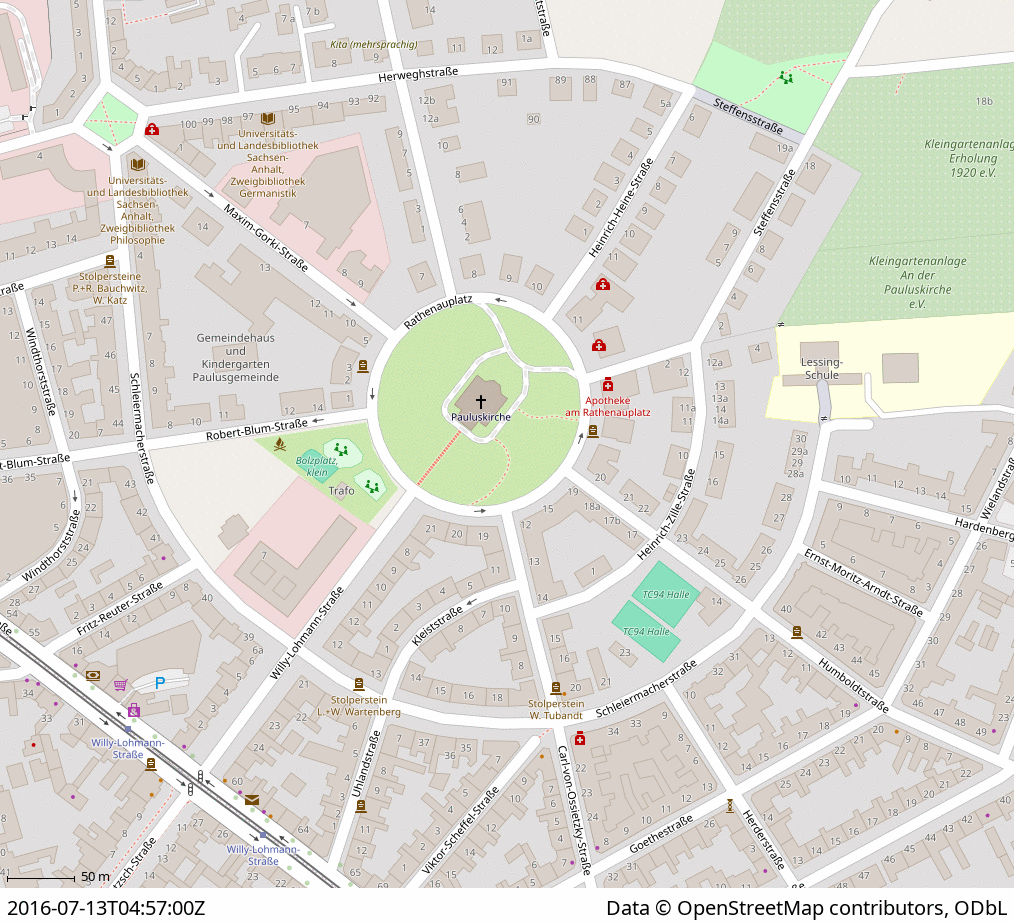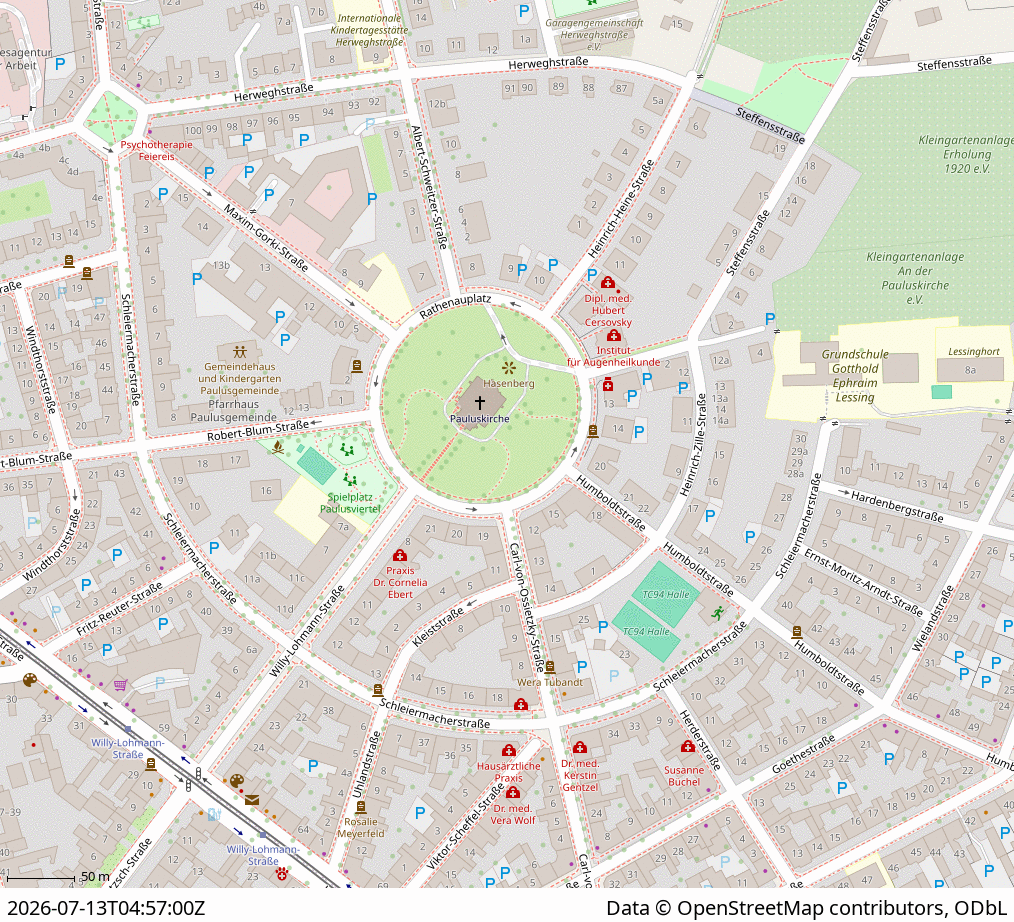
Wolltest Du auch schon immer mal wissen, wie sich die OSM-Daten an einer bestimmten Stelle verändert haben, also eine OSM-Zeitreise machen? Das ist jetzt mit der „before/after map“ auf mapki [1] ganz einfach möglich. Lass Dir einfach den „sign-in“-Link schicken, nutze diesen und suche Dir Dein gewünschtes Gebiet auf der OSM-Karte aus. Dann noch schnell ein Rechteck zeichnen, den gewünschten Zeitraum eingeben und schon hast Du die erforderlichen Eingaben gemacht. Nur noch starten und einige Zeit später bekommst Du einen neuen Link mit der Ergebniskarte.
Ich hab’s probiert, in Halle (Saale), Paulusviertel für den Zeitraum von vor 10 Jahren bis heute. Man muss etwas geduldig sein, bei mir hat es ca. 2:25 h gedauert, vielleicht war auch gerade viel los, aber das tolle Ergebnis [2] zählt, siehe auch Animation oben. Die deutlichsten Veränderungen: Pauluspark, Trafohaus auf dem Spielplatz entfernt, Parkmöglichkeiten ergänzt, Rembrandtstraße vervollständigt, mehr Läden und Praxen erfasst.
Bitte das Update (13.07.2026, 14:09 Uhr) beachten.
Wer Plugins für QGIS schreibt und in das zentral QGIS Plugin Repository [1] einstellen möchte, wird es in den letzten Monaten schon bemerkt haben. Beim Hochladen wird das Plugin sofort online nach verschiedenen Kriterien automatisch überprüft. So werden Checks bzgl. der Sicherheit, der Preisgabe von Geheimnissen und der Codequalität, etc. durchgeführt. Sicherheit und Geheimniserkennung müssen natürlich 100% erfüllt werden, bei der Codequalität werden ggf. Warnungen und Hinweise zu Verbesserung angeboten. Ich begrüße diese automatische Überprüfung ausdrücklich, sie macht einerseits die Plugins sicherer, erhöht deren Qualität und hat für uns alle den Vorteil, dass ein hochgeladenes Plugin bei bestandener Prüfung sofort, also nach wenigen Minuten für alle verfügbar ist.
Natürlich habe ich den Ehrgeiz, meine #geoObserverTools mit 100% durch diese Prüfung zu bekommen. Das klappt bei den ersten beiden Prüfungen auch wunderbar, nur bei der Prüfung der Codequalität scheitere ich immer wieder, leider. Es reicht zur Freigabe, aber nicht zu den angestrebten 100%, obwohl ich auch zur Sicherheit den Code noch mal im Python Formatter [2] prüfen und ggf. bereinigen lies. Warum?
Bei der Prüfung wird je nach Zustand entweder der Fehler W503 oder der Fehler W504 angezeigt. Aus meiner Sicht widersprechen diese sich aber inhaltlich, hier ein Beispiel:
Folgender Code erzeugt die Fehlermeldung: W504 – line break after binary operator
if not ( isinstance(times, list) and isinstance(temp, list) and isinstance(rain, list) ):
Der umgestellte Code erzeugt die Fehlermeldung: W503 – line break before binary operator
if not ( isinstance(times, list) and isinstance(temp, list) and isinstance(rain, list) ):
Bisher habe ich keine Lösung gefunden, auch die KI meldet:
„In Python, W503 and W504 are Flake8 style warnings that conflict with each other regarding line breaks and binary operators (e.g., +, -, and, or). They are disabled by default, but cause issues when enabled via configuration.
W503: Warns against a line break before a binary operator.
W504: Warns against a line break after a binary operator.
Modern code styling standards recommend breaking before the operator to keep code aligned Line break occurred after a binary operator (W504). Because of the conflict, the generally accepted fix is to disable one of the warnings in your project settings Flake8 – line break before binary operator.“
Ich habe zwei Anfragen gestellt, eine in der QGIS-Developer-Liste [3], die andere als GitHub-Issue [4]. Imho kann nur eine der Prüfungen zum Erfolg führen, nicht beide zusammen. Leider kamen noch keine auflösenden Antworten. Falls Ihr eine Lösung kennt, bitte lasst uns teilhaben, gern im Kommentarbereich. Oder sehe ich vielleicht nur den Wald vor lauter Bäumen nicht? 😉
Update 13.07.2026: Hier die Antwort im GitHub, die Regeln sollen deaktiviert werden [5]
Laut Informationen von Jürgen E. Fischer [1] stehen seit Mittwoch, dem 08.07.2026 die Pakete unter Linux, Windows und Mac für die QGIS-Releases 3.44.12 „Solothurn“ (LTR) and 4.2.0 „Belém do Pará“ (nächste LTR) auf qgis.org [2] zum Download [3] bereit. Alle Änderungen und Bugfixes sowie neue Funktionen findet Ihr im Changelog [4] und im Visual Changelog [5].
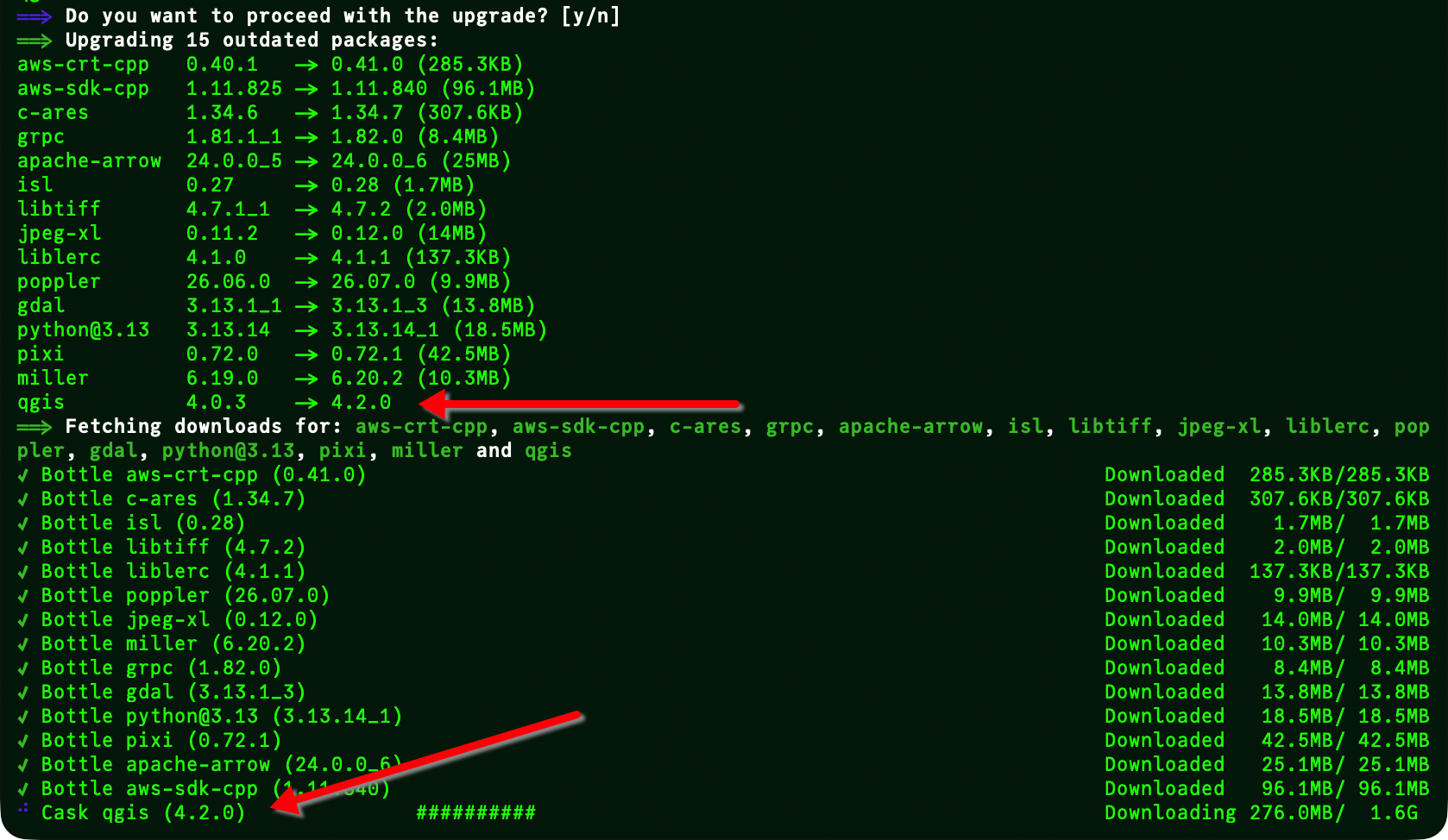
Via der Paketverwaltung „HomeBrew“ konnte ich bereits am Wochenende auf dem Mac die neue Version von QGIS 4, die v4.2 installieren. Der erste Start und die ersten Test liefen wie gewohnt problemlos. Mich haben natürlich dann auch gleich meine #geoObserverTools [6] inkl. dem GeoBasis_Loader [7] interessiert, würden sie auch unter v4.2 laufen? Ja, alle liefen auf Anhieb 🙂
Screenshot 2: Die QGIS-Installation via HomeBrew auf dem Mac, hier noch beim Download
Um mich nun aber mit der neuen QGIS-Version vertraut zu machen, habe ich mir im zweiten Schritt sofort den QGIS 4.2 – Visual Changelog [5] angeschaut, auf Youtube, wie immer 😉
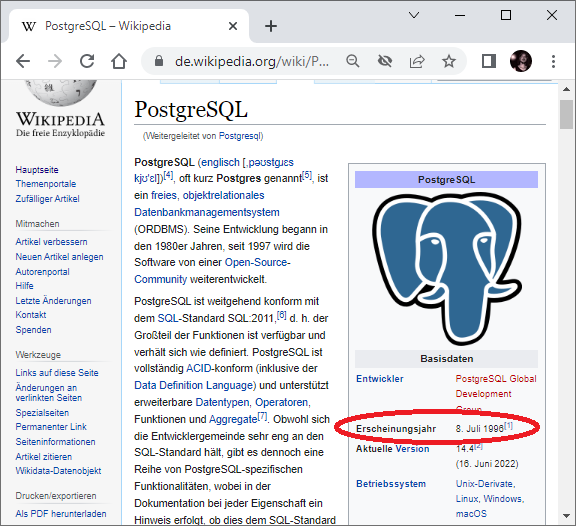
Der 8. Juli 1996 ist laut Wikipedia PostgreSQL-Geburtstag [1]. PostgreSQL [2], die mächtigste freie Datenbank hat allen Grund, ihren 30. zu feiern. Darum auch vom #geoObserver:
Herzlichen Glückwunsch, vor allem DANKE an alle Mitwirkenden und bitte weiter so!
Ich selbst nutze Dich seit 2001, also seit 25 Jahren und immer exclusiv, wenn es um Datenbanken geht! Du bist ein Kernstück unserer KomGIS+Suite [3], Deine Integration ins freie QGIS ist traumhaft!
Heute wieder mal ein Gastbeitrag, diesmal von meinem Fachkollegen Torsten Wolff, Geo- und Metadatenspezialist sowie Vorstandsmitglied im netzwerk | GIS Sachsen-Anhalt. Danke Torsten!
Von sandigen Römerpfaden zu kursächsischen Postmeilensäulen: Meilensteine, die Geschichte schreiben
Ein Meilenstein [1] – das klingt erstmal nach einem großen, steinernen Ding, das irgendwo am Straßenrand steht. Ein Meilenstein ist eigentlich ein wichtiges Ereignis oder Ziel, das du auf deinem Weg erreichst. Stell dir vor, du wanderst durchs Leben wie durch einen Wald, und plötzlich siehst du ein Schild: “Hier hast du 5 km geschafft – herzlichen Glückwunsch!” Genau das ist ein Meilenstein: ein Punkt, an dem du sagen kannst: “Boah, ich hab’s geschafft!”
Screenshots: Meilensteine aus Wikipedia (Bildquellen [1])
Wer hat die Meilensteine erfunden?
Jetzt wird’s spannend! Die Idee der Meilensteine stammt aus der römischen Antike – ja, die mit den Sandalen und den ganzen Imperien, die sie aufgebaut haben. Die Römer waren nicht nur gut im Straßenbau (stell dir vor, du baust eine Straße, die 2.000 Jahre hält – Respekt!), sondern sie hatten auch eine clevere Idee: Sie markierten ihre Straßen mit Steinen, die den Abstand zur nächsten Stadt oder zum nächsten wichtigen Ort anzeigten – also die ersten Wegweiser oder Navigationssysteme.
Diese Steine sahen aus wie kleine Säulen und hießen – tadaa – „Miliarium“ (lateinisch für Meilenstein) [2]. Auf ihnen stand meistens etwas wie: “Von hier aus sind es 12 Meilen bis Rom“. Die Römer waren also die ersten, die sagten: “Hey, Leute, wir tracken mal, wie weit ihr gekommen seid!”
Meilensteine in Sachsen: Die Postsäulen
Und jetzt wird’s sachsen-spezifisch! In Sachsen gibt es nämlich eine ganz besondere Art von Meilensteinen: die Postsäulen. Diese Säulen wurden im 18. und 19. Jahrhundert aufgestellt und dienten nicht nur der Wegemarkierung, sondern auch der Orientierung für Postkutschen und Reisende. Sie waren oft aus Sandstein gefertigt und zeigten die Entfernung zu wichtigen Städten wie Dresden, Leipzig oder Meißen an.
Ein besonders bekanntes Beispiel ist die „Kursächsische Postmeilensäule“ – ein Meisterwerk der barocken Wegemarkierung [3]. Diese Säulen waren nicht nur praktisch, sondern auch kunstvolle Denkmäler. Heute sind viele dieser Postsäulen noch erhalten und erinnern an eine Zeit, in der das Reisen noch Abenteuer und Geduld erforderte.
Warum sind Meilensteine heute noch wichtig?
Heute nutzen wir den Begriff nicht mehr nur für Steine am Straßenrand, sondern für jeden wichtigen Schritt in einem Projekt, einer Karriere oder sogar im Leben. Ob du eine Prüfung bestehst, dein Haus fertig gebaut hast oder endlich den Kühlschrank aufräumst – das sind alles Meilensteine!
Und das Beste? Du kannst sie selbst setzen! Egal, ob groß oder klein: Jeder Fortschritt zählt. Also: Welchen Meilenstein hast du als Nächstes vor?
Fun Fact zum Schluss: Der berühmteste Meilenstein der Geschichte ist wahrscheinlich der „Goldene Meilenstein (Miliarium Aureum)“ [4] in Rom. Der stand im Forum Romanum und markierte den Punkt, von dem aus alle Straßen in Italien gemessen wurden. Aufgrund dieser Säule entstand das Sprichwort „Alle Wege führen nach Rom“. Heute ist er leider verschwunden – aber sein Geist lebt weiter in jedem Projektplan, jedem Lebenslauf und jedem “Ich hab’s geschafft!”-Moment. Und in Sachsen? Da lebt er weiter in den Postsäulen, die noch heute von der Geschichte und dem Fortschrittsgeist erzählen!
IT-Service Torsten Wolff
Zum Autor: Torsten Wolff lebt seit 1988 in Magdeburg, ist seit 2006 selbstständig und betreut seit über 20 Jahren Informationssysteme und Internetportale im Umweltbereich sowie im Rahmen der Metadaten-, Geodateninfrastruktur und Open Data für die öffentliche Verwaltung. Er ist Stakeholder im Softwareentwicklungsprozess (Metadateneditor, Portal) der Open-Source-Software InGrid OSS / Portal METAVER (MetadatenVerbund). Diese wird in einer Kooperation aus Bundesländern, Bundesbehörden und einem kommunalen Dienstleister entwickelt. Er ist außerdem Vorstandsmitglied des Vereins Netzwerk GIS Sachsen-Anhalt e. V., der sich für die Förderung des Einsatzes von Geoinformationssystemen (GIS) und die Entwicklung von Geodateninfrastrukturen (GDI) in Sachsen-Anhalt einsetzt. Und er ist immer an neuen, interessanten und kuriosen Dingen aus der Geowelt interessiert. https://it-service-magdeburg.de/
Screenshots: Die Röntgen-Symbole (Bildquellen [4])
Röntgen [1] ist ein Set von Icons, um verschiedene Kartenelemente aus der OpenStreetMap-Datenbank darzustellen. Es lässt sich jedoch auch problemlos für beliebige Kartenprojekte oder auch für Vorhaben, die ggf. nichts mit Karten zu tun haben, verwenden. Derzeit besteht das Set aus 569 Icons. Alls Icons stehen im SVG-Format zur Verfügung, eine Nachnutzung in Eurem GIS, z. B. QGIS ist damit unproblematisch möglich. Sergey (enzet) hat auf Mastodon [2] mitgeteilt, dass jetzt Version 0.16.0 [3] von Röntgen veröffentlicht wurde. Das komplette Icon-Set könnt Ihr als ZIP auf GitHub [6] herunter laden.
Der GeoInteressierte legt möglicherweise Wert darauf, seine Geoaffinität auch offen zu zeigen. Wem es ebenso so geht, der sollte sich mal MapOnShirt [1] mit den verschiedensten Varianten der OpenStreetMap-Visualisierung auf verschiedenen Produkten anschauen, dort heißt es
Fantastische Kartendesigns MapOnShirt ist ein tolles Tool, mit dem man farbenfrohe Designs aus Landkarten erstellen und diese in hochwertige Artikel verwandeln kann – T-Shirts, Poster, Kissen und mehr. „Es ist der ideale Ort für durchdachte Geschenke und originelle Wohnaccessoires.“ [1]
Screenshot 2: Mein erster #geoObserver-Prototyp, an den Farben ist selbstverständlich noch zu arbeiten 😉 (Bildquelle [1])
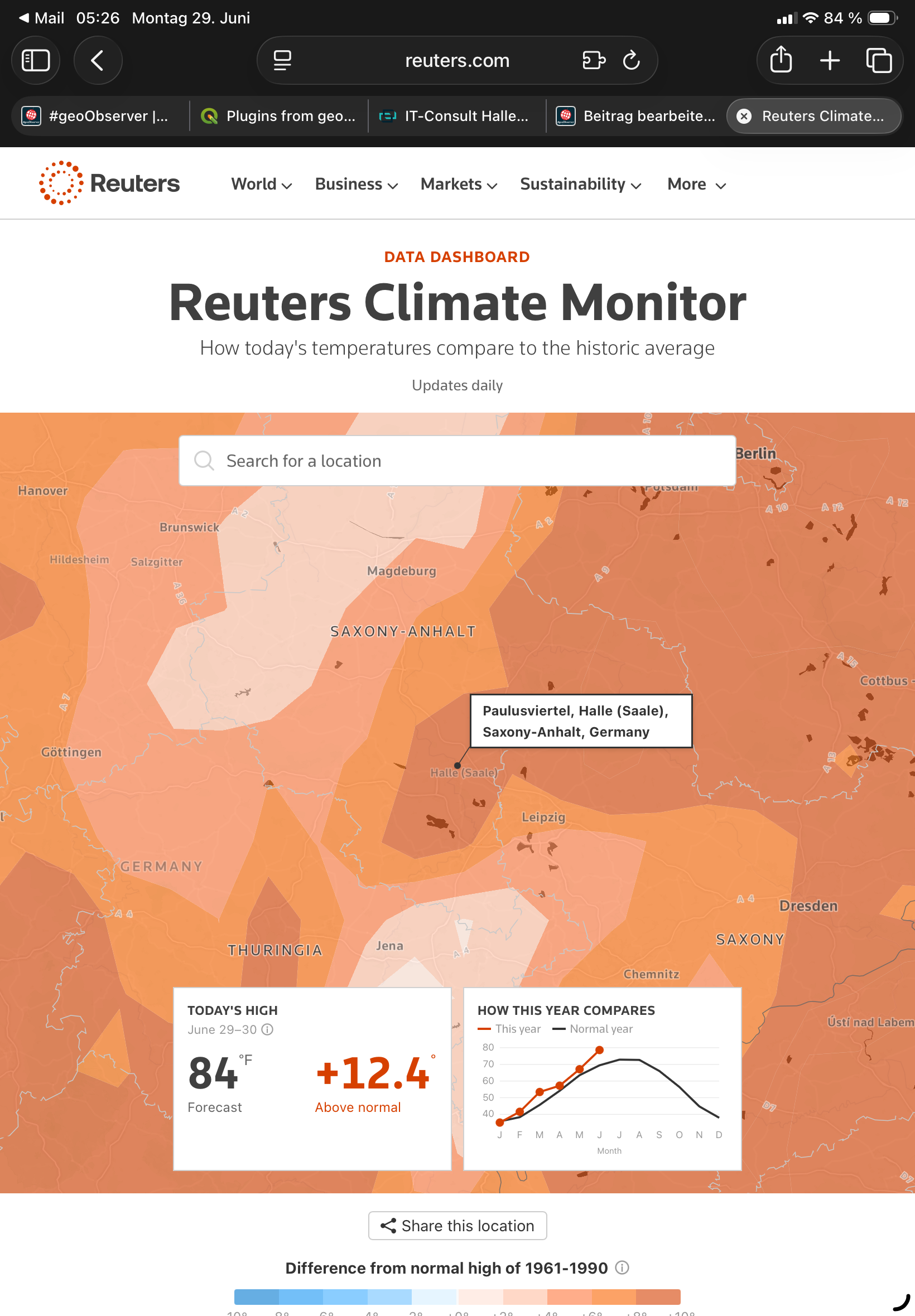
Screenshot 1: 12,4° wärmer als der langjährige Durchschnitt von 1961-1990 im Paulusviertel in Halle (Bildquelle [1]) – Angaben in Fahrenheit
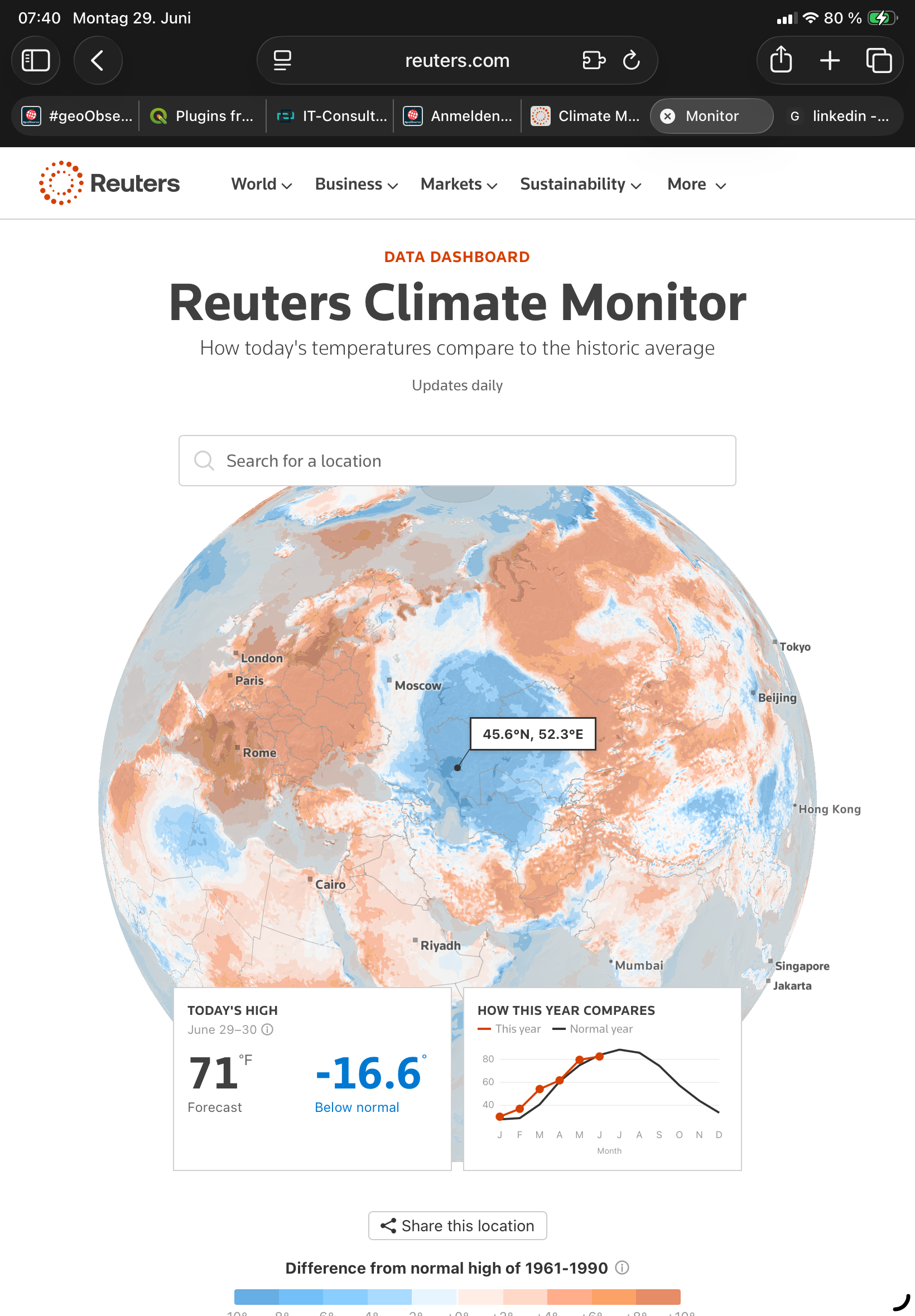
Heute soll es sich ja nun endlich abkühlen, hoffen wir mal! Auf jeden Fall merken wir, es wird wirklich Ernst und ist es ein passender Moment, sich mit der Klimaproblematik noch intensiver auseinanderzusetzen. Dabei hilft ein neues, einfach zu bedienendes und verständliches Dashboard, welches uns die wirklich erschreckenden Daten – wirklich gut visualisiert – verdeutlicht, der neue Reuters Climate Monitor [1]. Dort heißt es:
Der Reuters Climate Monitor zeigt in Echtzeit, wo die Temperaturen ungewöhnlich heiß oder kalt sind, indem er die heutigen Bedingungen mit denen vergleicht, die in der Vergangenheit typisch waren. [1]
Screenshot 2: Aber auch anders, 16,6°weniger aus der langjährige Durchschnitt von 1961-1990 in Kasachstan (Bildquelle [1]) – Angaben in Fahrenheit
Update: Bitte beachtet die Umschaltmöglichkeit zwischen den Temperatur-Angaben in Fahrenheit und Celsius. In den Screenshots werden Angaben in Fahrenheit angezeigt.