„Die vollständig überarbeitete und erweiterte 2. Auflage von „KI in Geodäsie und Geoinformatik“ bietet einen fundierten Überblick über aktuelle Verfahren, Konzepte und Anwendungsfelder der künstlichen Intelligenz im Kontext von Geodäsie und Geoinformatik. Ein interdisziplinäres Autorenteam aus 70 Expertinnen und Experten stellt bewährte und neu entwickelte Methoden vor und zeigt, wie KI die Erfassung, Verarbeitung und Analyse von Geodaten nachhaltig verändert.“ und „Dieses Werk bietet eine wissenschaftlich präzise und praxisnahe Gesamtdarstellung der aktuellen Entwicklungen der Geospatial AI und richtet sich gleichermaßen an Entscheider, Fachleute, Forschende und Studierende in Geodäsie, Geoinformatik, Geomarketing, Geowissenschaften und verwandten Disziplinen.“ [4]
Ich jedenfalls bin gespannt und kann es gar nicht erwarten, selbst ein Exemplar des Gemeinschaftswerkes von 70 ExpertInnen in den Händen zu halten. Bis dahin.
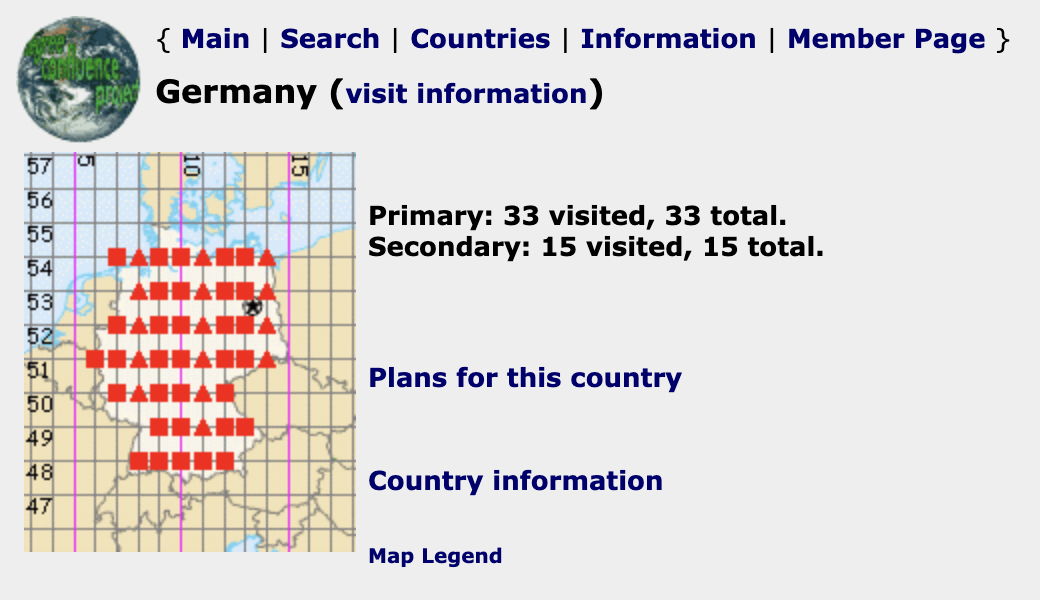
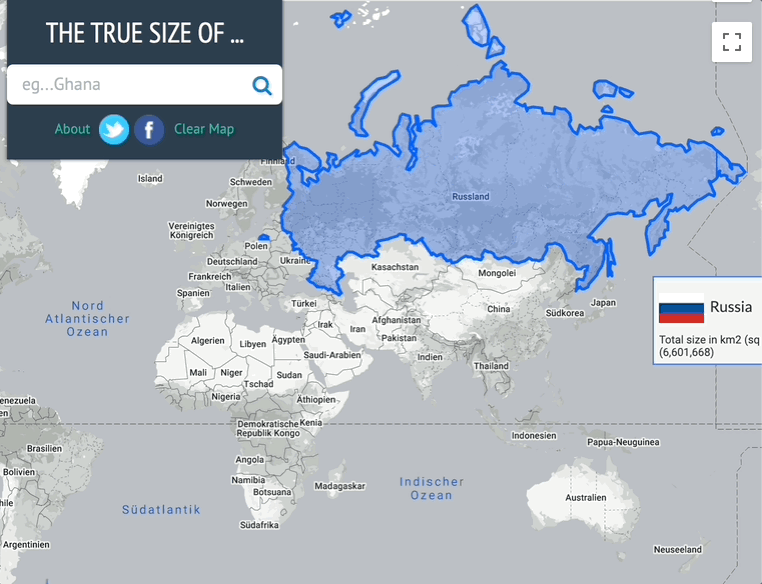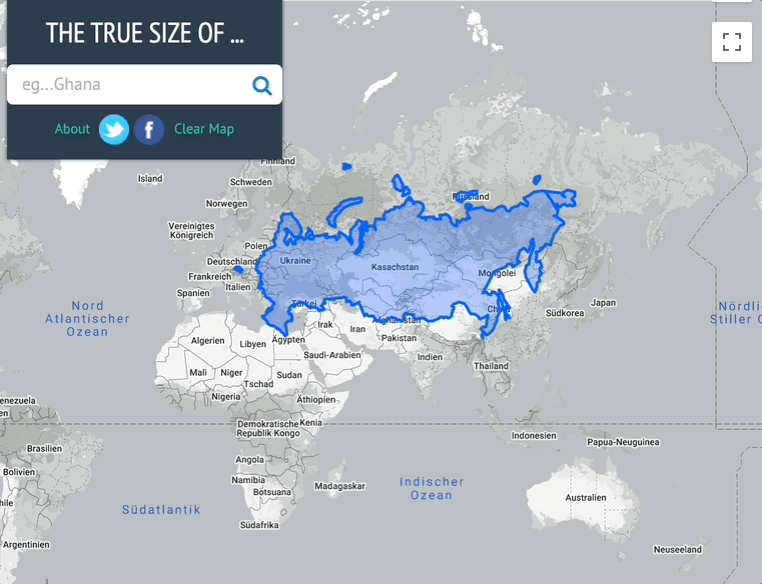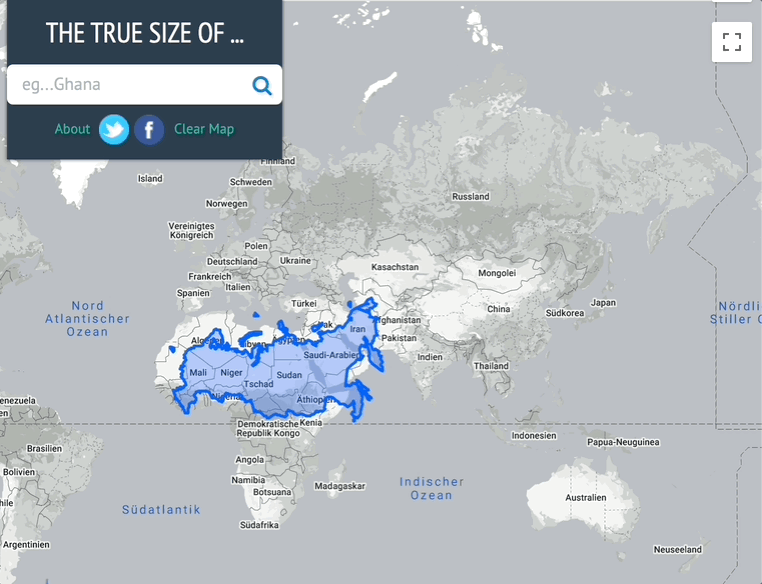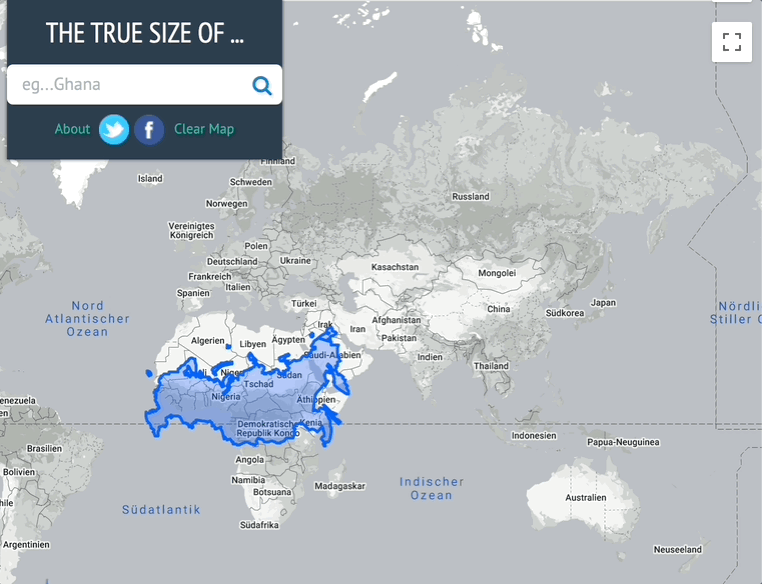
Screenshot 1: Konfluenzpunkte in Deutschland (Bildquelle [3])
Die meisten kennen sicherlich Geocaching. Aber mit den GPS im Handy oder als Gerät lassen sich auch andere Dinge finden, z. B. ein Konfluenzpunkt, der „Schnittpunkt eines ganzzahligen Längengrades mit einem ganzzahligen Breitengrad auf der Erdoberfläche.“ [1]. Und es gibt sogar ähnlich dem Geocaching ein weltweites Projekt dazu, das „Degree Confluence Project“ [2]. Ziel im Projekt ist es, diese Orte zu besuchen und zu fotografieren und dann die Fotos online zu veröffentlichen. Übrigens: Im Umkreis von 79 km um eines jeden Standorts gibt es einen Konfluenzpunkt. Nach Abzug der Konfluenzpunkte in den Ozeanen und einige in der Nähe der Pole, es gibt immerhin 9.635 zu entdecken. Zu den Konfluenzpunkten in Deutschland [3] und Sachsen-Anhalt [4].
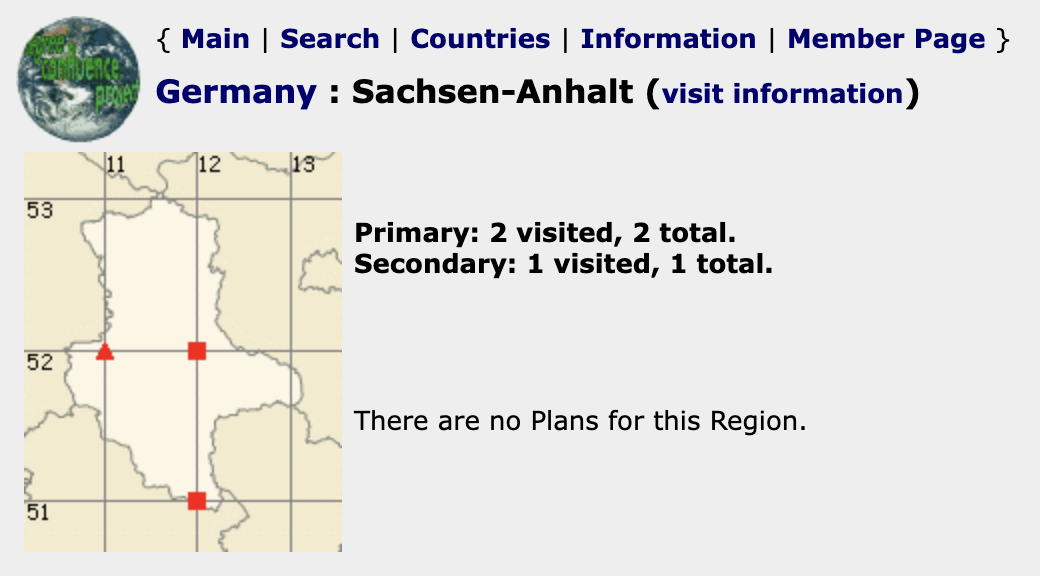
Screenshot 2: Die drei Konfluenzpunkte in Sachsen-Anhalt (Bildquelle [4])
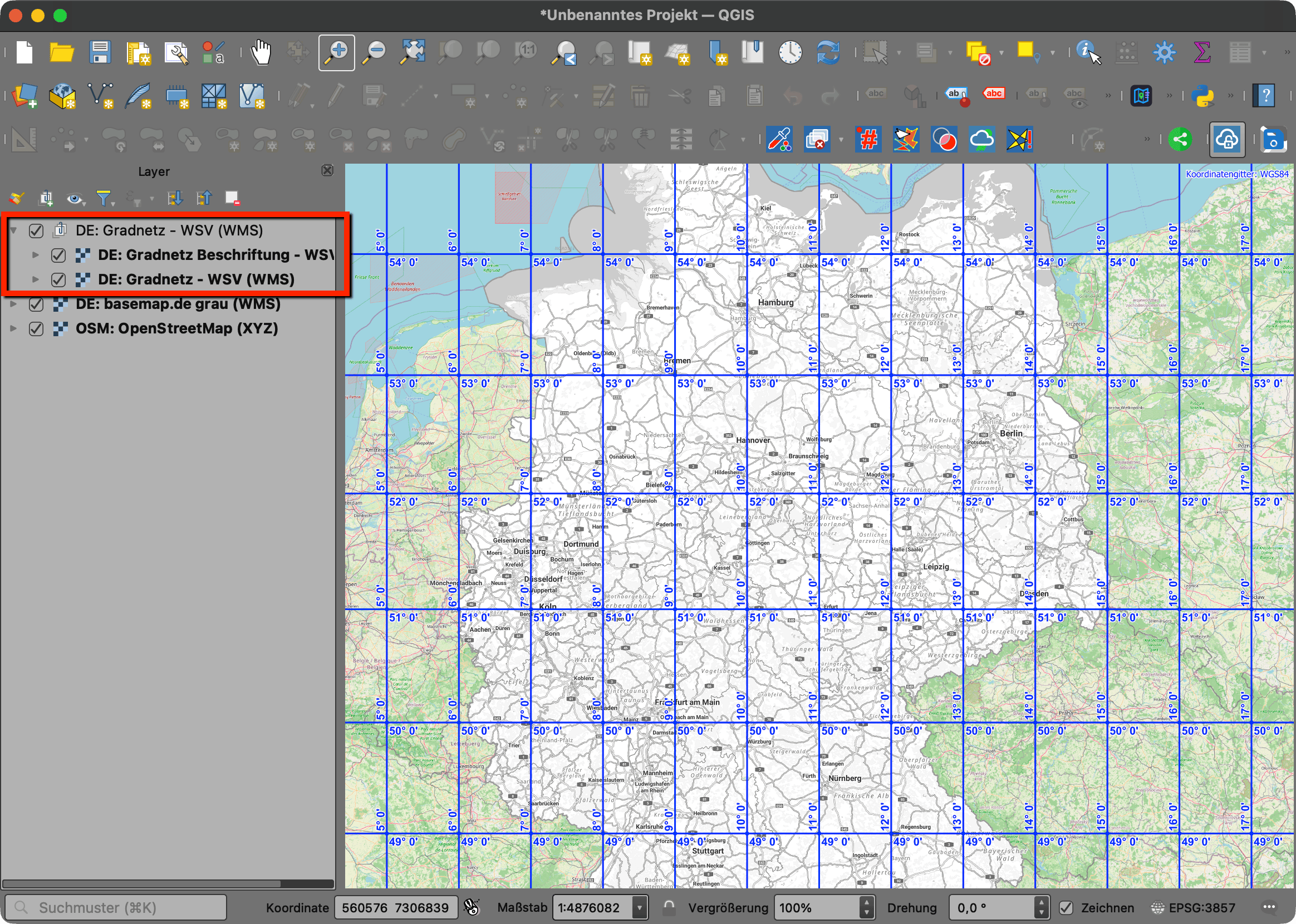
Alle QGIS-Nutzer können mit dem GeoBasis_Loader [5] im engeren europäischen Raum über das Thema „DE: Gradnetz“ im Katalog 1 die Konfluenzpunkte einfach und schnell visualisieren.
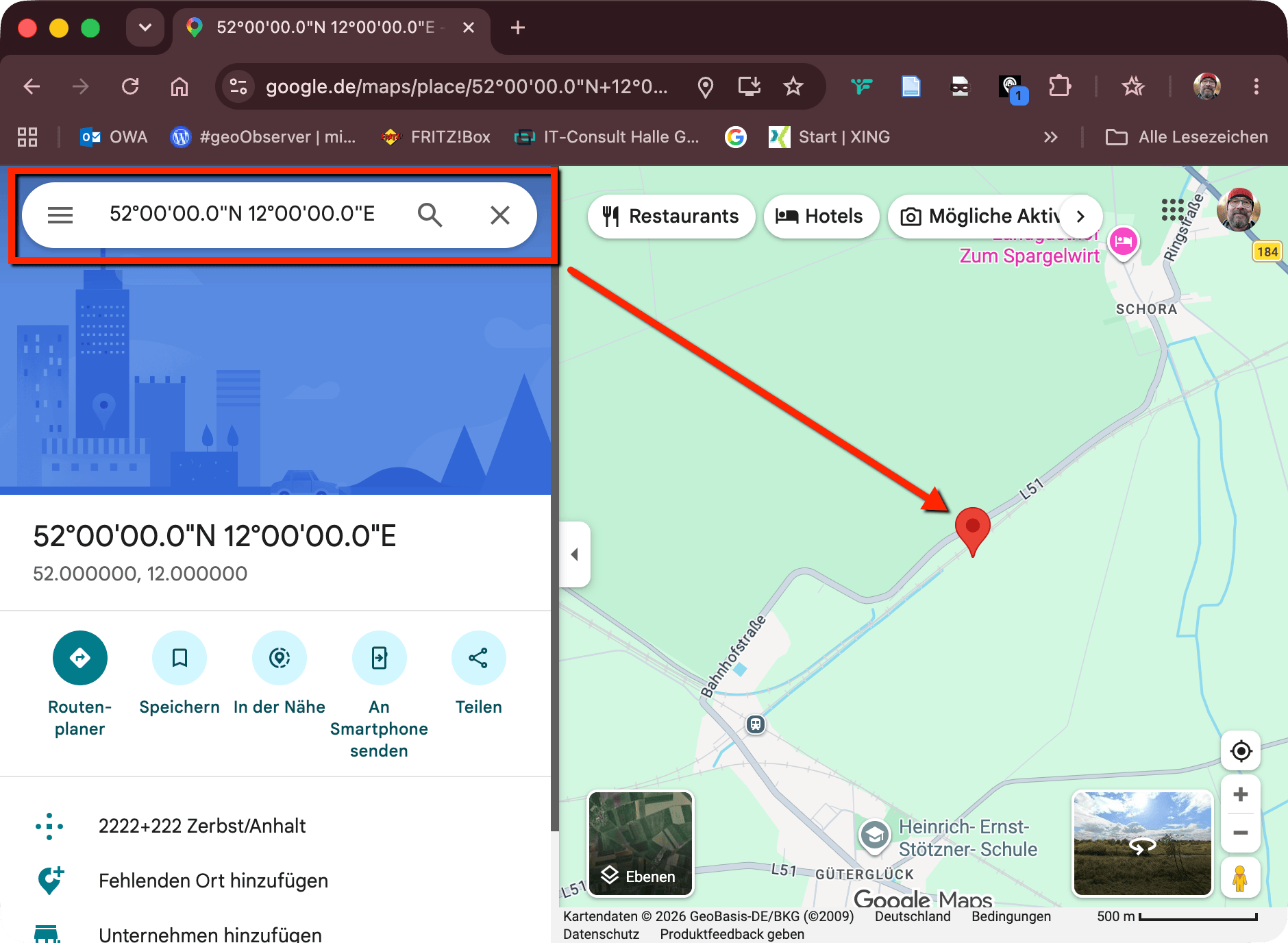
Auch in den einschlägigen Online-Kartenwerken findet man die Konfluenzpunkte ganz schnell, ich habe hier imGoogle Maps nach „52,12“ gesucht und glatt wird die exakte Position angezeigt.
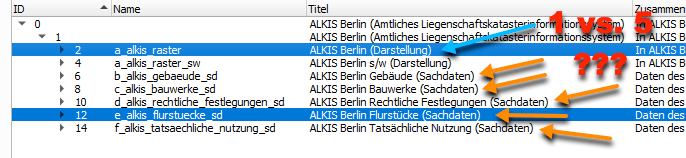
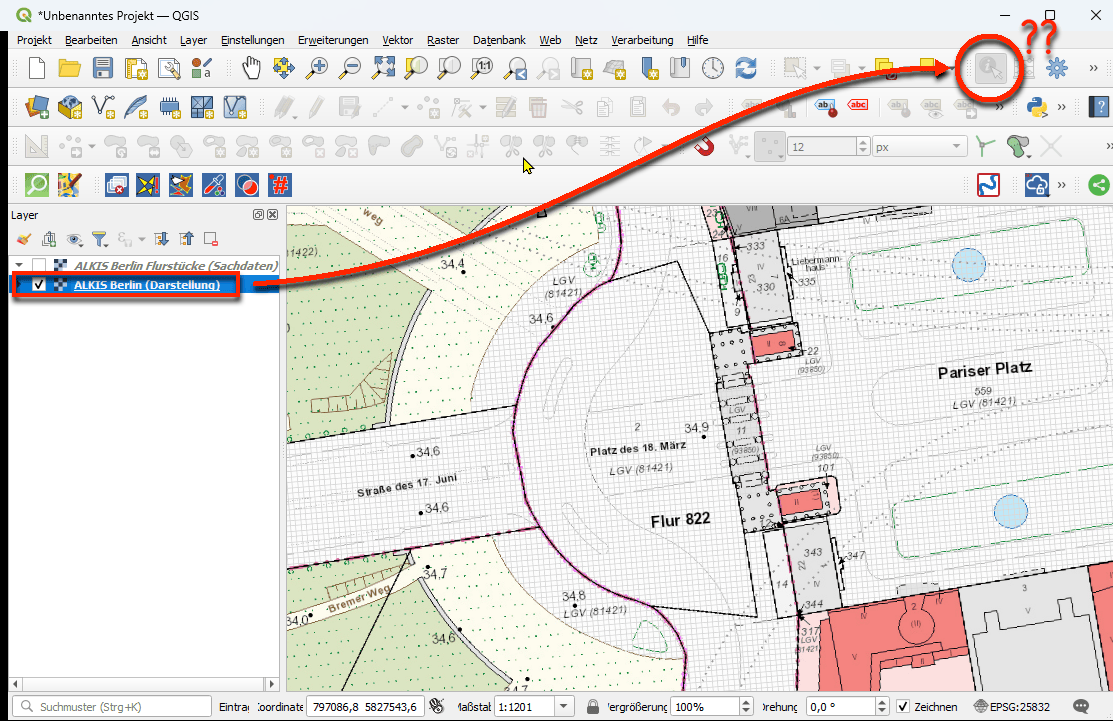
ALKIS Berlin: Ein Darstellungslayer vs. 5 Sachdatenlayer in einem WMS, warum?
Also eigentlich dachte ich, ich kenne mich mit OGC-konformen Geodiensten ganz gut aus. Nun bin ich aber in Berlin (IMHO ein echter Open Data Vorreiter!) auf einen im März 2026 aktualisierten ALKIS-WMS [1] gestoßen, den ich in dieser Form noch nicht erlebt habe und eigentlich so auch nicht verstehe. Warum betreibt man einen WMS anders als vom Standard vorgesehen?
Ein WMS zeichnet sich lt. Wikipedia durch folgenden Eigenschaften aus:
„Im Sinne eines verteilten Geoinformationssystems (GIS) besitzt ein WMS nur die Fähigkeit zur Auskunft der notwendigen Metainformation, zur Visualisierung dieser Geodaten und für eine allgemeine Abfrage der zugrundeliegenden Sachdaten.“ [2]
Bekanntermaßen liefert mir ein WMS eine Karte mit GetMap (ein georeferenziertes Bild als PNG, GIF, JPG, TIFF, …) und gleichzeitig auf Anfrage die Sachdaten eines Objektes über einen abgefragten Punkt (Koordinate) in diesem Dienst mit GetFeatureInfo. Des Weiteren können noch die Legende mit GetLegendGraphic und die Eigenschaften mit GetCapabilities abgefragt werden.
In Berlin macht man es nun aber plötzlich anders. Hier werden die Inhalte zur Visualisierung für die Flurstücke, Gebäude, Bauwerke, … in einem Layer gemischt und die Sachdaten getrennt in weiteren fünf Layern, immerhin alles in einem Dienst vorgehalten, einer für die gemischte Karte (GetMap) und die fünf für die Sachdaten (GetFeatureInfo). Aber warum? Das heißt ja für den Nutzer in seinem GI-System immer mindestens zwei Layer laden, einen mit der Karte ohne Sachdaten, um die Geodaten überhaupt zu sehen und den zweiten, eben mit leerer Karte, nur, um die Sachdaten via Identifikation abfragen zu können. Das bringt
die Nutzer durcheinander,
erhört den Aufwand,
senkt die Transparenz,
konterkariert IMHO die WMS-Philosophie und
ist doch eigentlich total unnötig, oder?
Ich hätte je einen Layer für Flurstücke, einen für Gebäude, Bauwerk, Nutzung, etc. erwartet, jeweils mit Karte und Sachdaten, so wie üblich und in allen anderen Bundesländern auch realisiert, üblicherweise getrennt nach Flurstücken, Gebäuden und tatsächlicher Nutzung. Für GIS-Insider ist das vielleicht gewöhnungsbedürftig, aber machbar, für „normale“ Endkunden ohne spezielle GIS-Kenntnisse im WebGIS wie OpenLayers, Leaflet oder MapLibre eine Zumutung.
Hier die Problematik für das Thema „Flurstücke“ mal bebildert:
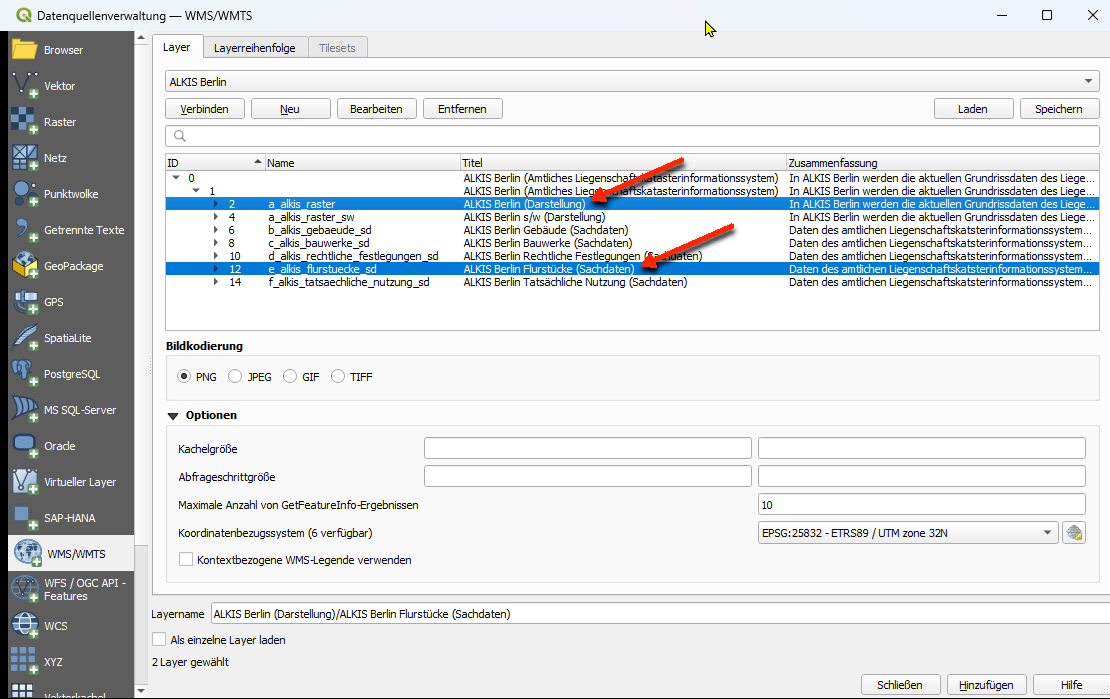
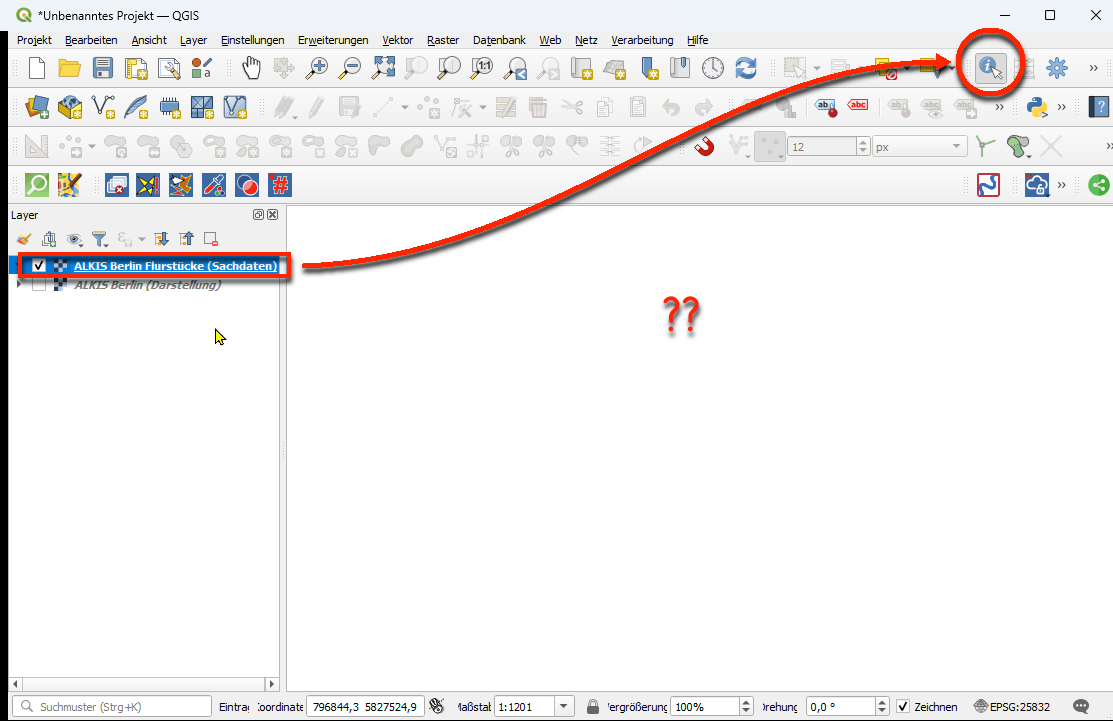
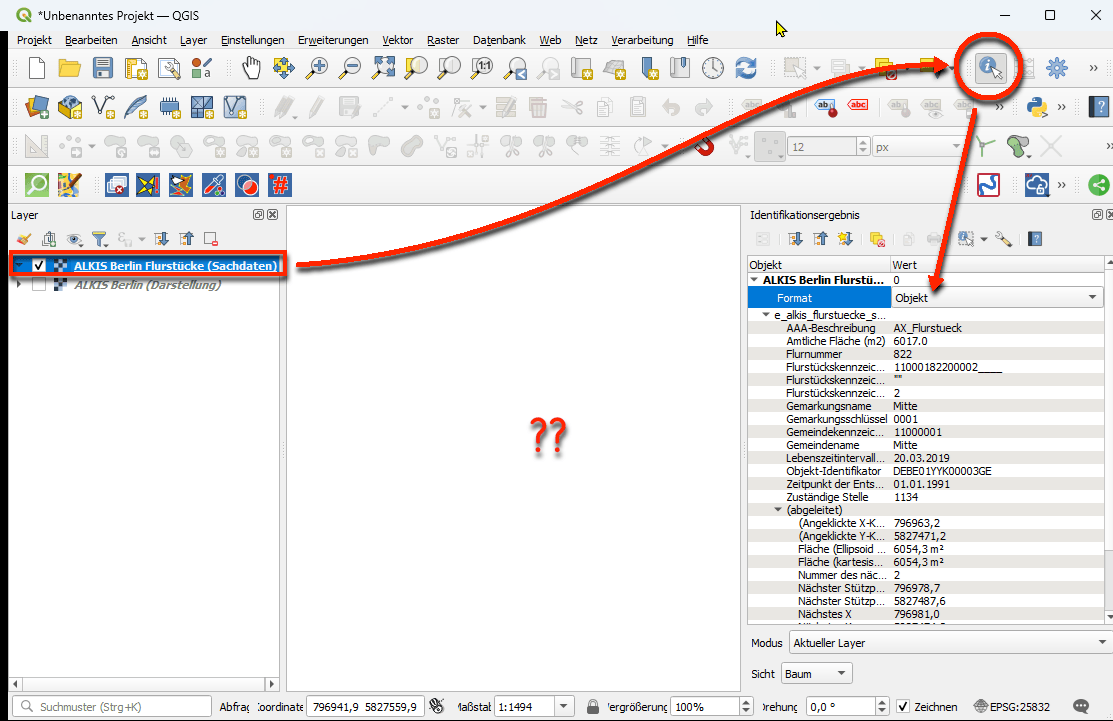
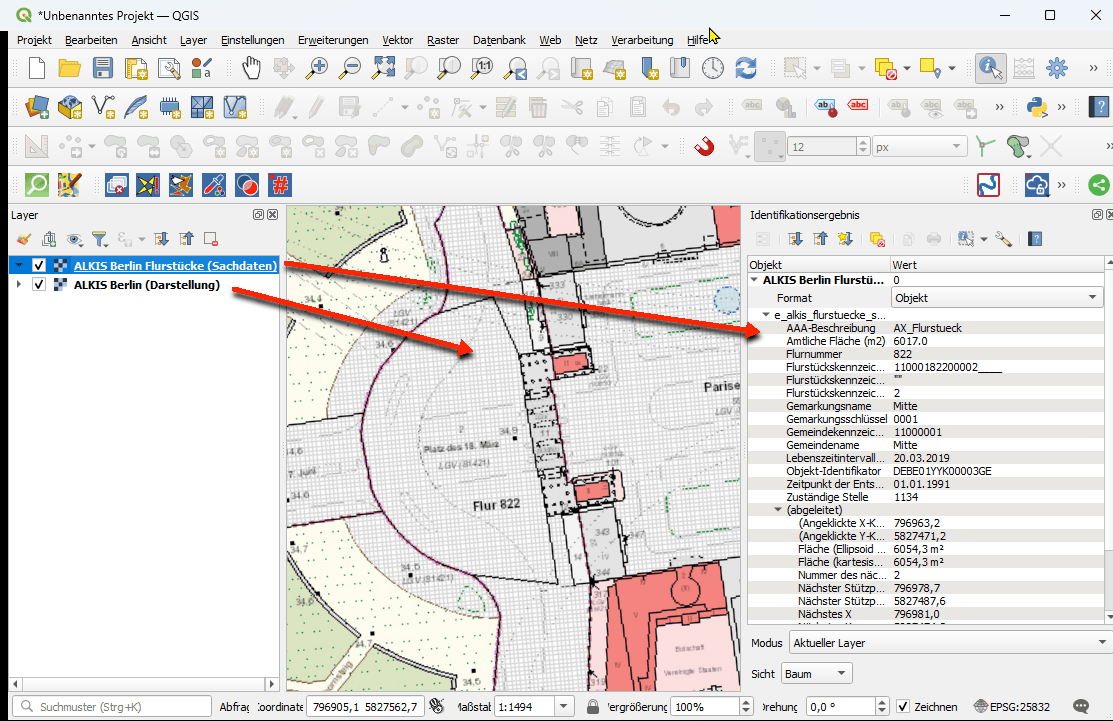
Screenshot 1: Die zwei verschiedenen Layer für die gemischte „Darstellung“ und die Flurstücks-„Sachdaten“ im QGISScreenshot 2: Nur der Layer für „Darstellung“ leider ohne IdentifikationsmöglichkeitScreenshot 3: Nur der Flurstücks-Layer für „Sachdaten“ leider ohne KarteScreenshot 4: Nur der Flurstücks-Layer für „Sachdaten“ identifizierbar aber leider ohne KarteScreenshot 5: Beide Layer für gemischte „Darstellung“ und Flurstücks „Sachdaten“ und nur bei richtiger Aktivierung (blau) auch mit Identifikationsergebnis
Ich habe mich mit einigen Fachkollegen dazu ausgetauscht, keiner hatte eine Idee oder plausible Erklärung. Und was macht man heute, man befragt die KI, meinen Chat dazu findet Ihr in [3]. Aber auch dort bin ich nicht wirklich fündig geworden. Der noch plausibelste Grund für verschiedene Toleranzen sollte bei Flurstücken, Gebäuden, … eher keine Rolle spielen, diese Objekte trifft man per Mausklick im Allgemeinen immer sicher.
Vielleicht können uns die Berliner Kollegen mal auf die Sprünge helfen, warum sie das so (ungewöhnlich) gelöst haben, gern in den Kommentaren. Ich jedenfalls bin gespannt und lerne gern dazu!
Übrigens, über den für mich unverständlichen, weil unterschiedlichen Umgang mit inhaltlich gleichen Themen in den einzelnen Bundesländern habe ich in meinem Vortrag „Open Data in D: Perfekte Idee, halbherzige Umsetzung? Ein Erfahrungsbericht.“ auf der FOSSGIS 2025 in München [4], [5] das erste Mal berichtet, dann immer mal wieder.
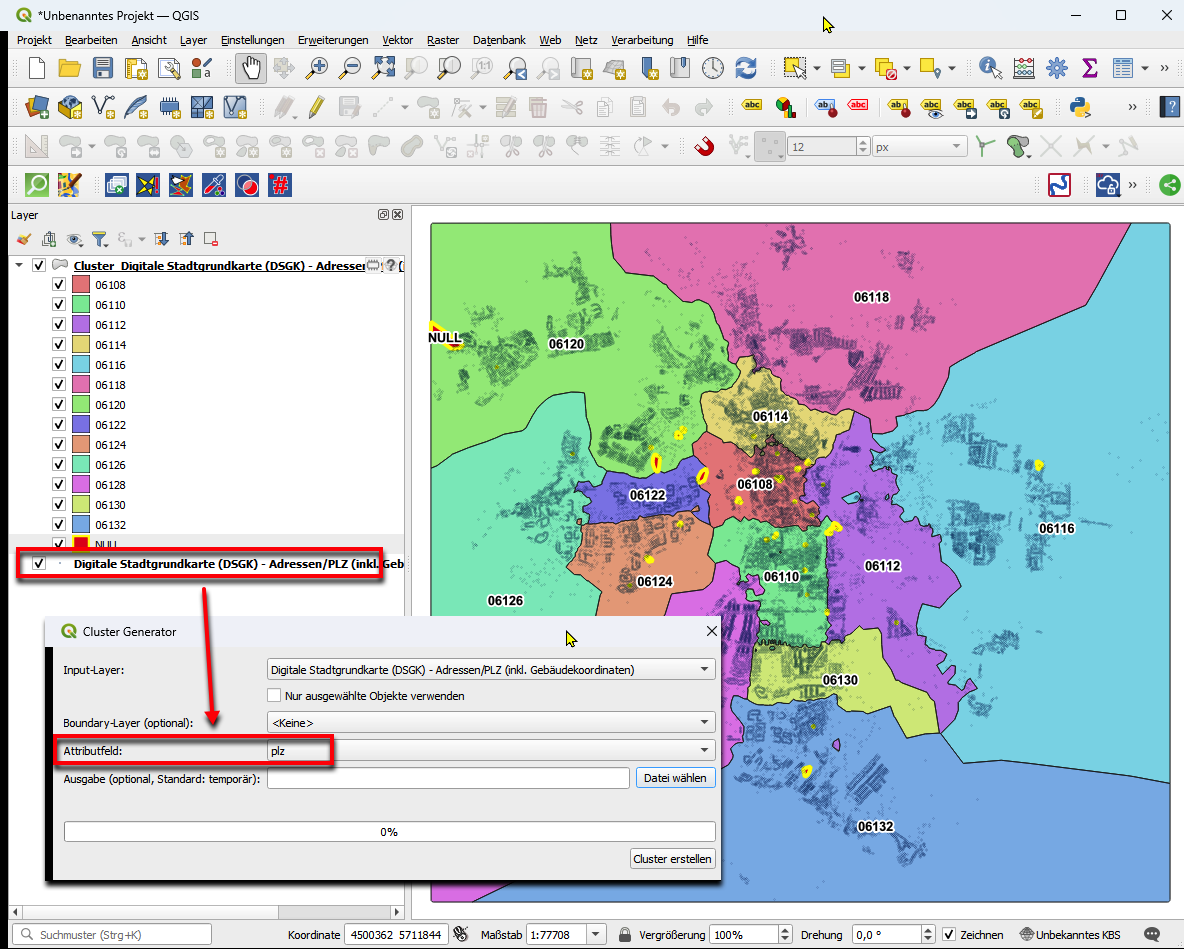
Mitunter kann man viel Zeit benötigen, um Daten zu prüfen. Eine häufig verwendete Methode ist dabei, die Objekte mit demselben Attributwert zu ermitteln und deren räumlichem Zusammenhang zu berechnen und zu visualisieren. Das kann dann u. U. wieder viel Zeit sparen. Man erstellt dazu s. g. Clusterflächen. Eine wirklich praktikable Lösung dafür liefert das neue QGIS-Plugin „Cluster Generator“ [1]
Screenshot 1: Mein Test, 34098 Punkte mit „plz“-Attribut geclustert
Ich habe das Plugin mal kurz angetestet, die Bedienung ist einfach und selbsterklärend. Genutzt habe ich dazu unseren Postleitzahlen- (PLZ-) Datenbestand. Der automatisch einmal pro Nacht generierte Datenbestand hat vfür Halle (Saale) momentan 34098 Punkte mit PLZen. Die Clusterfunktion darauf angewendet liefert recht schnell die Clusterflächen mit den PLZ-Bereichen und färbt und beschriftet diese automatisch nach dem ausgewählten Attributfeld, hier also „plz“. Das Formular und die Ergebnisse findet Ihr in Screenshot 1.
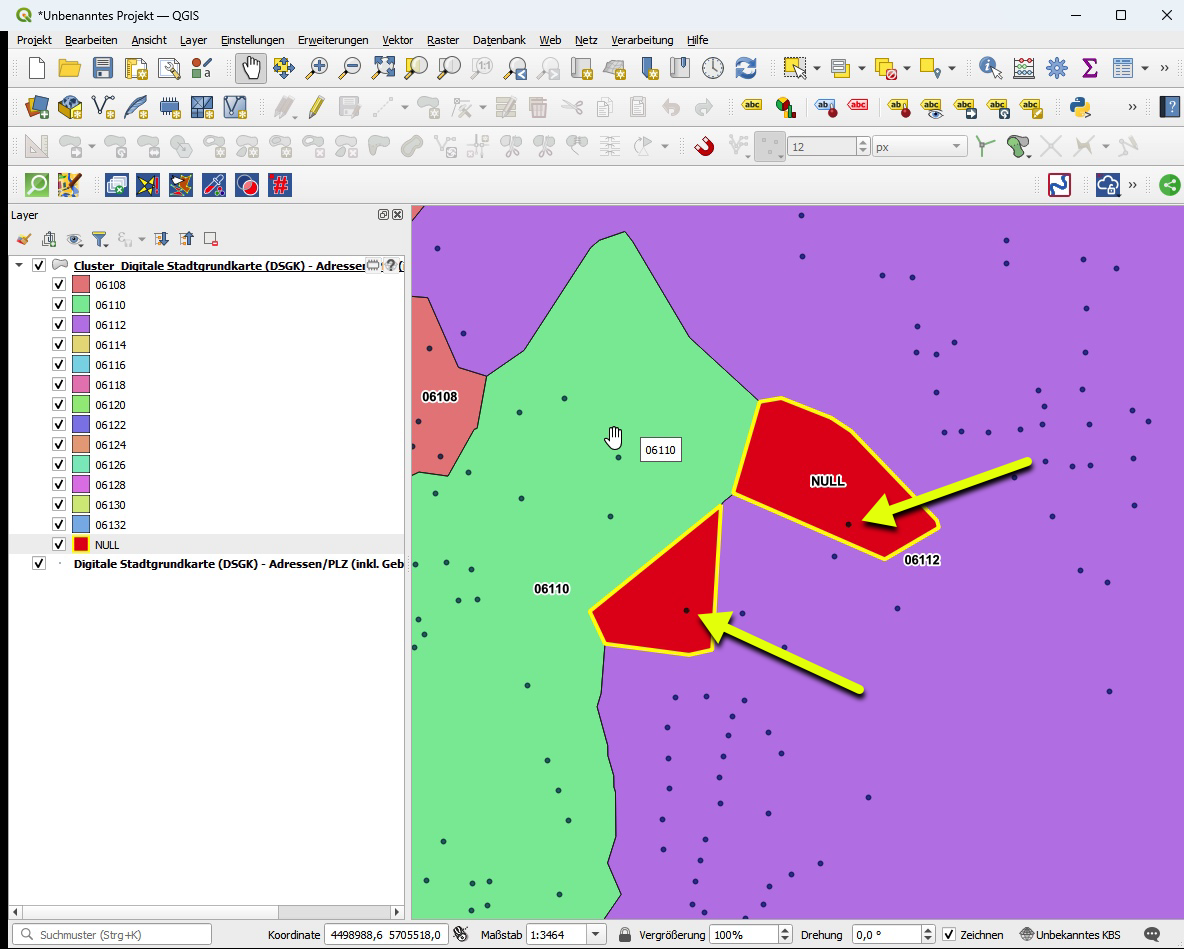
Ein wunderbarer, positiver Nebeneffekt. Man findet so auch ganz schnell, quasi nebenbei die fehlerhaften Objekte, bei meinem Test die Punkte mit dem Eintrag „plz=NULL“. Ich habe diese NULL-Flächen mal etwas hervorgehoben. Für die Punkte in diesen Flächen sind die PLZ-Attributwerte also zeitnah zu aktualisieren, von „NULL“ auf die tatsächliche PLZ oder die Punkte an sich sind zu überprüfen.
Screenshot 2: Fehlerhafte Punkte mit „plz=NULL“ in Extra-Clusterinseln
Über Fluch und Segen der Mercartor-Projektion [1] habe ich hier [2] schon oft berichtet. In den GIS-Schulungen erlebe ich immer wieder, dass sich die Teilnehmer das Ganze aber doch recht schwer vorstellen können. Deshalb habe ich mal nach guten Visualisierungen zur Mercartor-Problematik gesucht, einige seien hier vorgestellt.
Übrigens , wer sich selbst mal ein Bild machen will, dem sei TheTrueSize.com [3] empfohlen, hier habe ich mal Russland untersucht:
Die runde Erde auf eine Fläche projezieren, wie geht das und warum wird so unterschiedlich verzerrt? [4]
Grönland in verschiedenen Projektion, Mercartor verfälscht am meisten [8]
I haven't heared from Greenland for a while – so here is a smart map showing Greenland in various map projections – by @Kate Berg and @Sarah Bell from @pokateo_
Meine Leseempfehlung zum Thema: Wirkt der „Dark Mode“ in der Kartographie anders herum oder wie werden die Farben im immer mehr genutzten Dunkelmodus wahrgenommen? Während im Hellmodus dunklere Farben mit einer größeren Wertigkeit assoziiert werden, stellt sich die folgende Frage: Ist das im Dunkelmodus genau so oder, wie vielleicht zu erwarten, genau umgekehrt? Prof. Dr. Jochen Schiewe, Präsident der DGfK [1] hat es in einer mit 214 Personen durchgeführten Online-Studie untersucht. In seinem KN-Beitrag „Dark‑is‑More Bias Also in Dark Mode? Perception of Colours in Choropleth Maps in Dark Mode“ [2], als PDF downloadbar unter [3], sind die Ergebnisse veröffentlicht, also, wie die Farben im Hell- und Dunkelmodus auf die Probanden wirken. Ich spoilere mal nicht, lest selbst 😉 es lohnt sich. Nur eins dazu:
„Die Studienergebnisse erlauben auch generelle Gestaltungsempfehlungen für künftige Dunkelmodus-Farbschemata für Karten.“ [2]
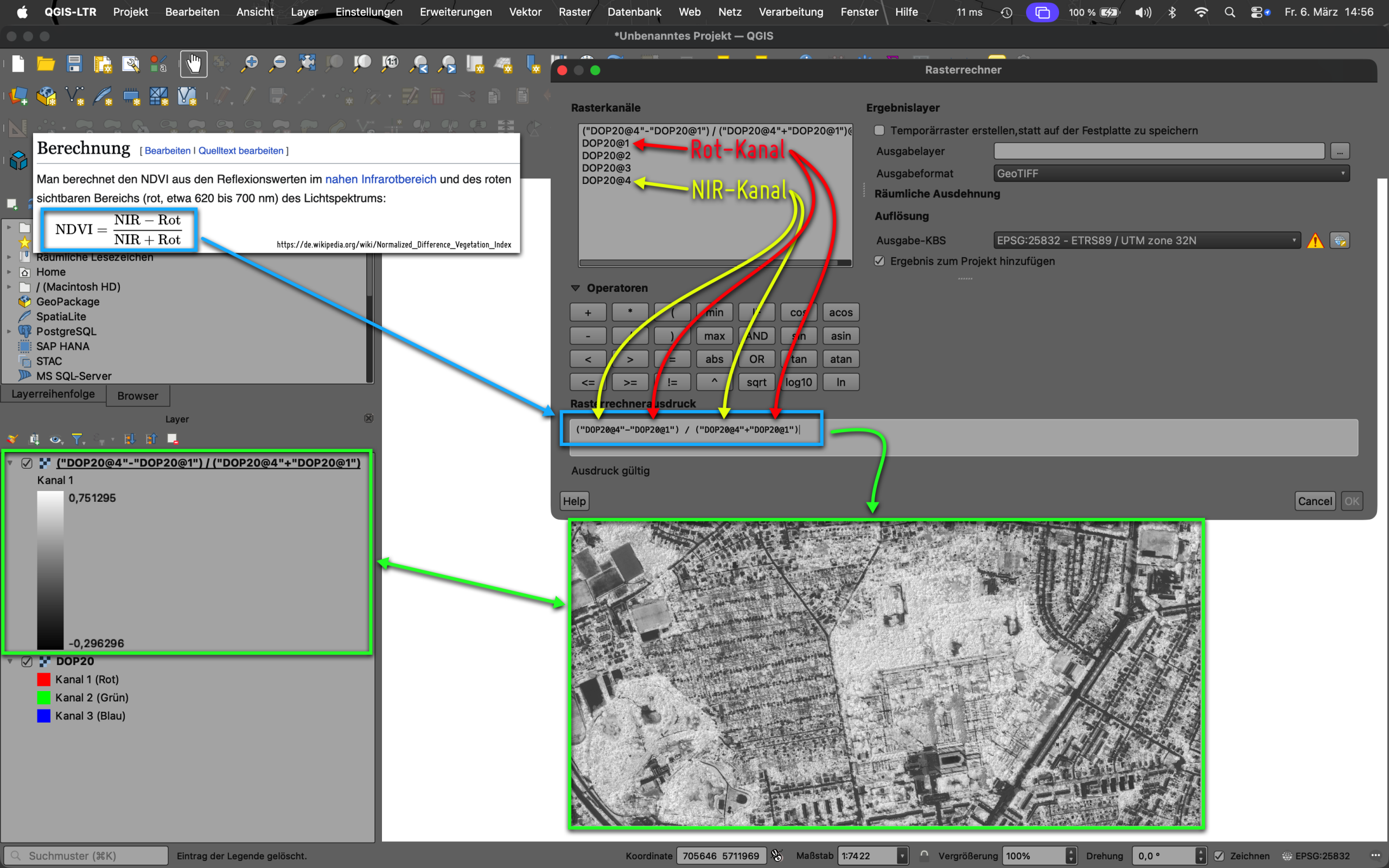
NDVI (Normalized Difference Vegetation Index) [1] ist lt. Wikipedia „der am häufigsten angewandte Vegetationsindex“ und ist seit Jahren ein Standardwerkzeug bei der Beurteilung von Fernerkundungsdaten. In vielen GI-Systemen ist er einfach zu berechnen mit der vergleichbar simplen Formel:
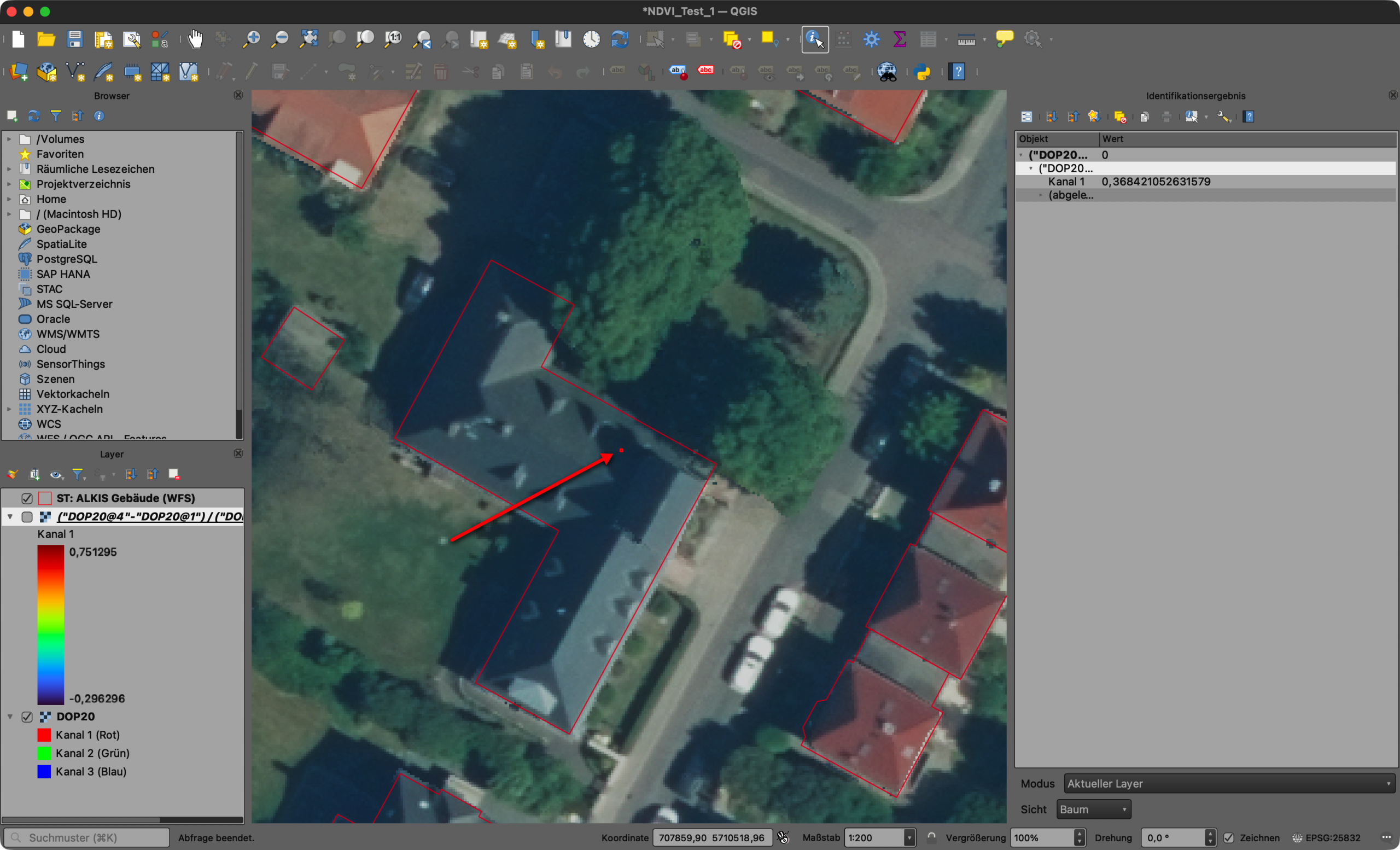
In QGIS kann diese Berechnung unkompliziert mit dem Rasterrechner realisiert werden. Ich habe das mit den vom LVermGeo LSA als freie DOP20-Luftbilder [2] angebotenen Daten getestet. Die Besonderheit hier: die DOP20 repräsentieren im Kanal 4 den benötigten NIR-Kanal. Folgender Screenshot zeigt die Vorgehensweise im QGIS-Rasterrechner mit den LSA-DOPs.
Screenshot 1: Umsetzung der NDVI-Berechnung im QGIS mit dem Ratserrechner
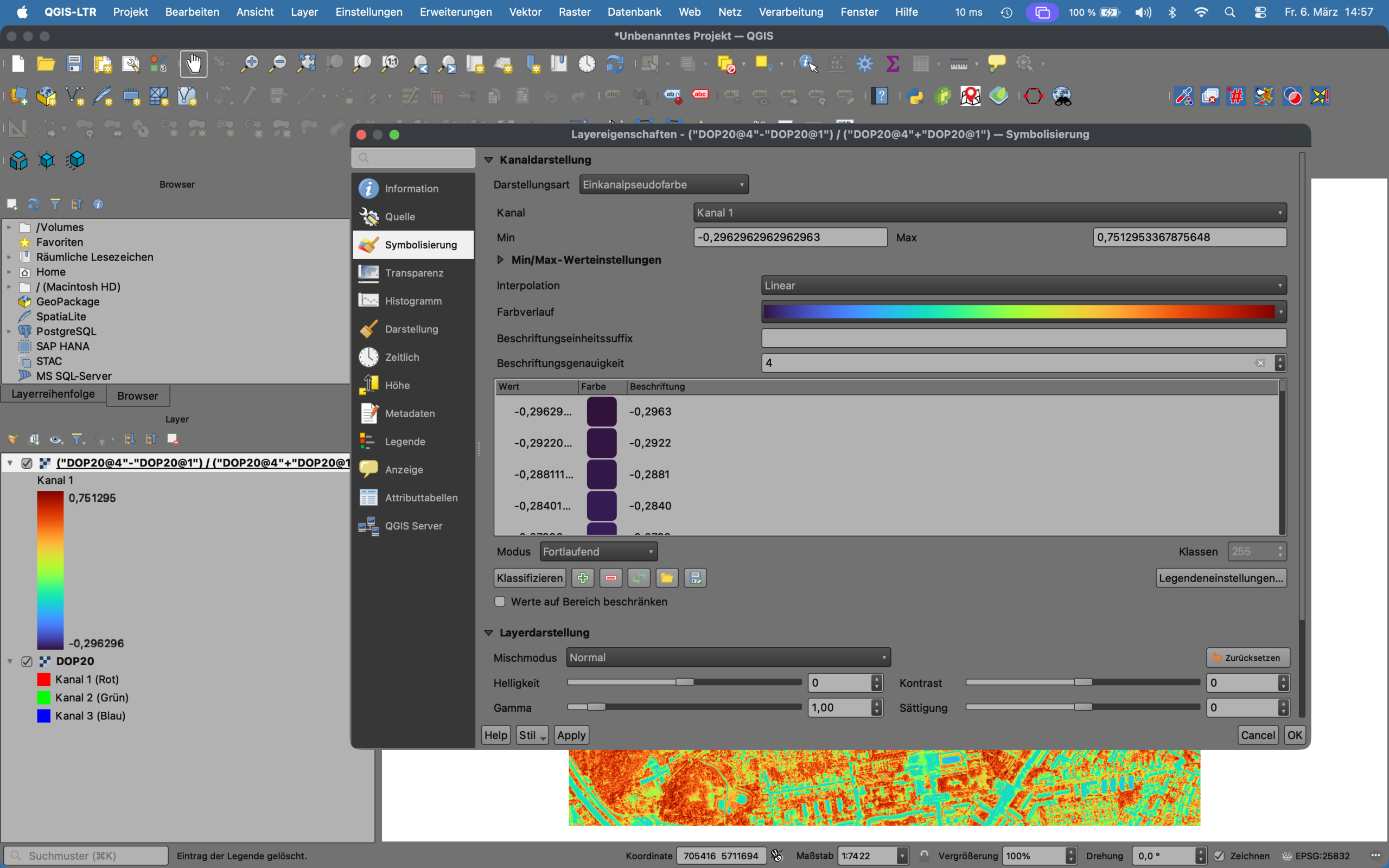
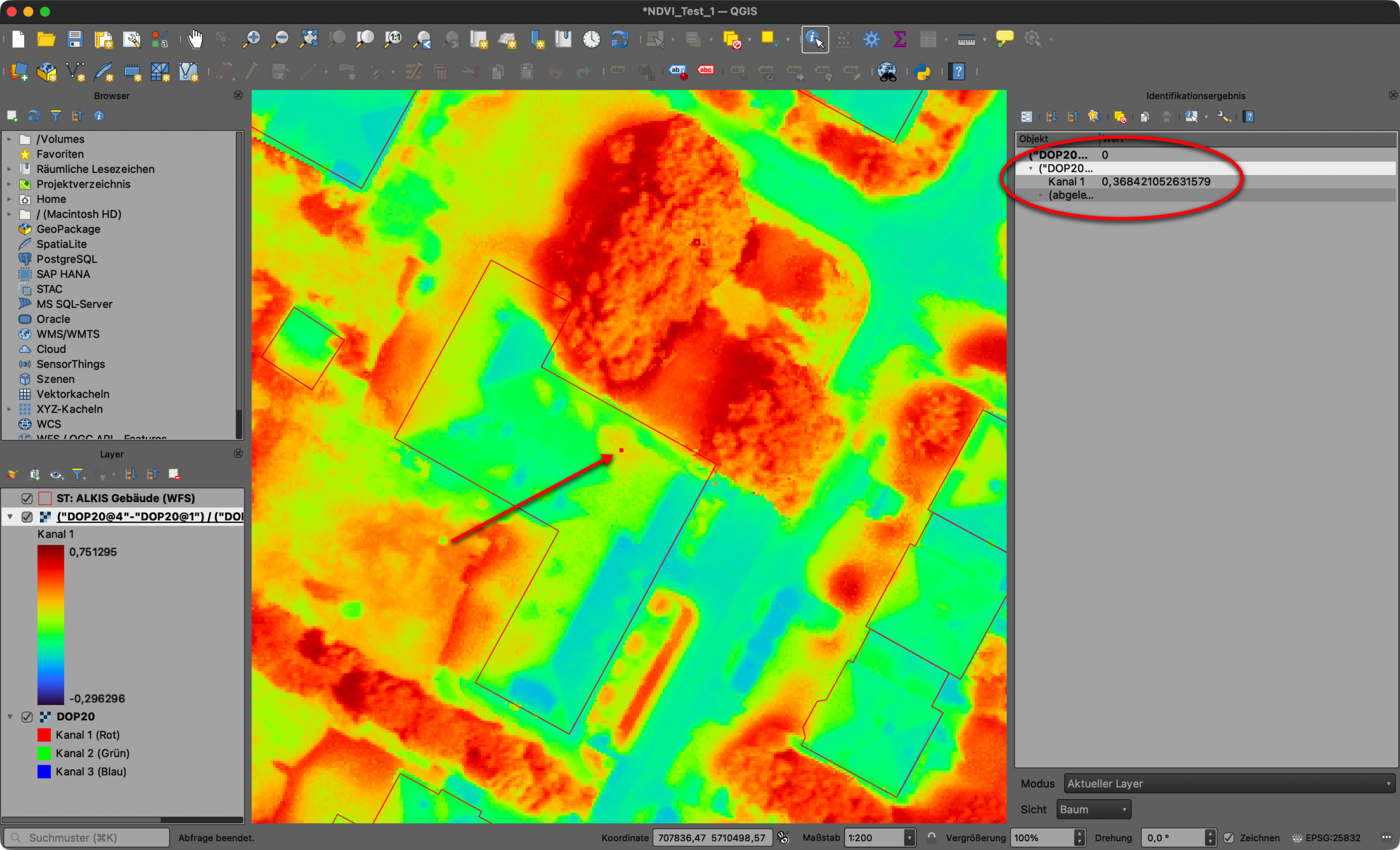
Um das Ergebnis der Berechnung, ein Graustufen-Bild, noch deutlicher zu visualisieren, kann das entstandene Raster z. B. als „Einkanalpseudofarbe“ eingefärbt werden. Die Klassen und Unterschiede im NVDI werden damit deutlich sichtbarer.
Screenshot 2: Einfärben des Graustufen-Ergebnisses als „Einkanalpseudofarbe“ im QGIS
Grenzen und Gefahren bei Fehlinterpretation:
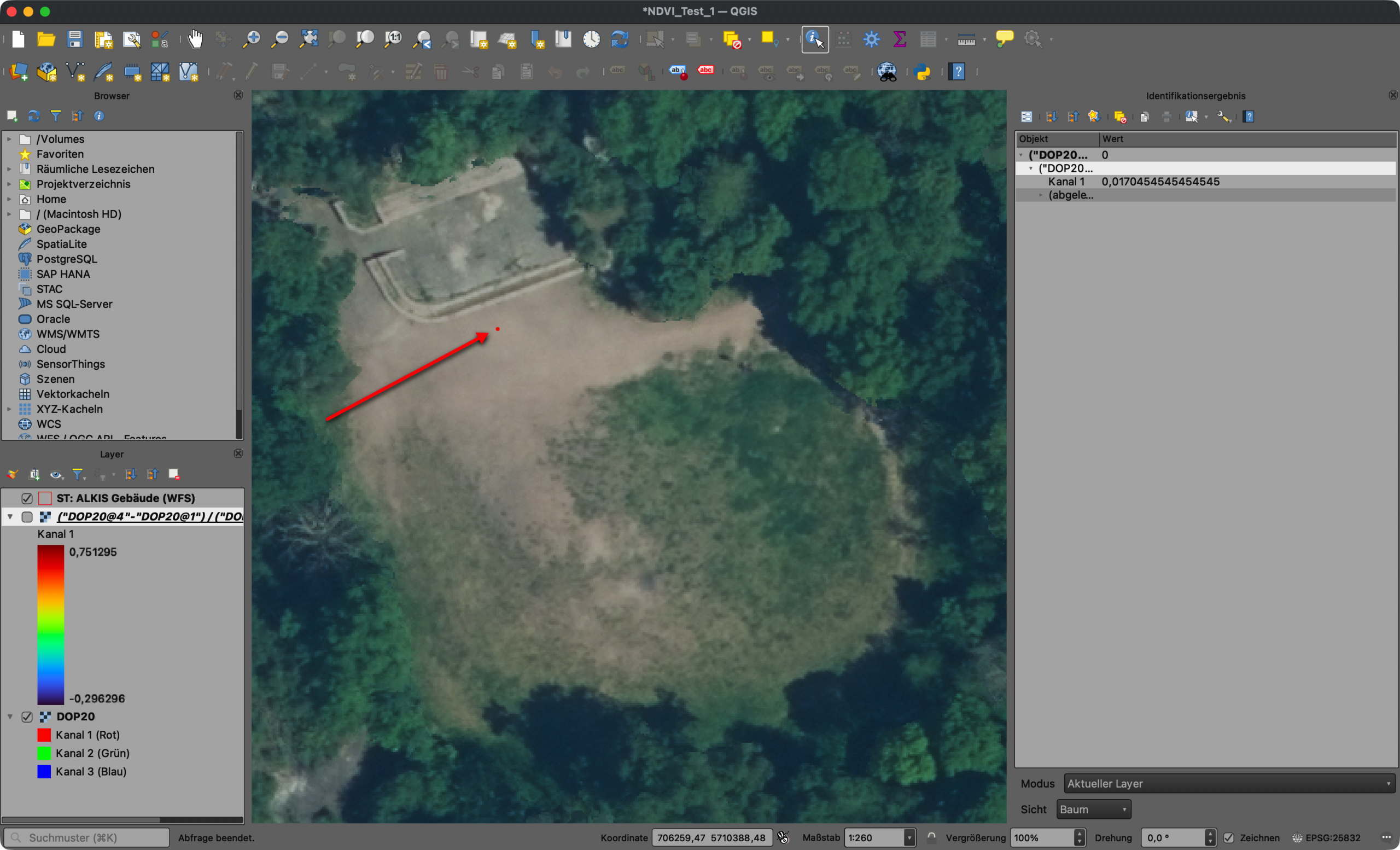
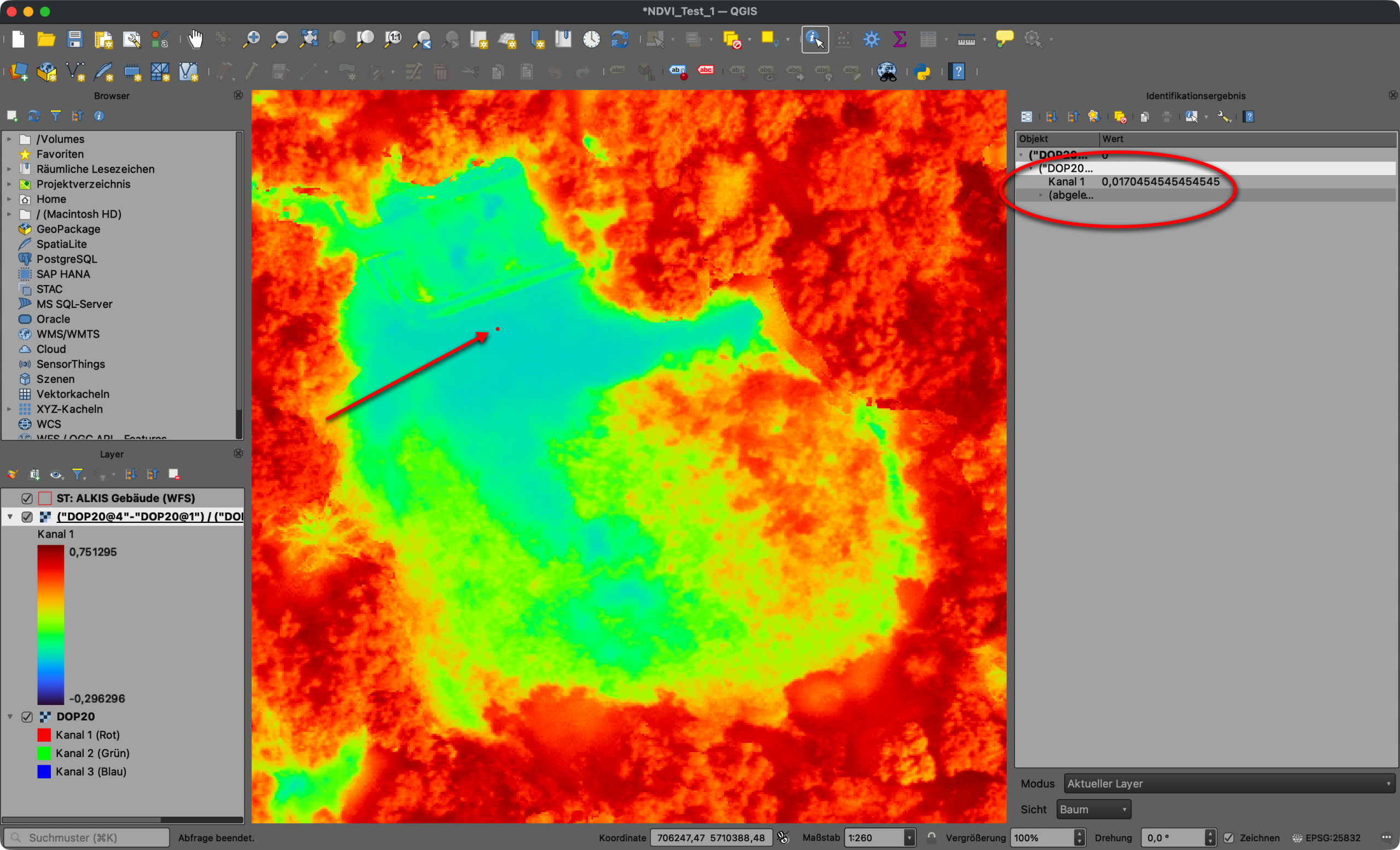
vertrocknete pflanzliche Strukturen (z. B. vertrocknete Rasenfläche)
Screenshot 3: Gefahr der Fehlinterpretation durch Verschattung (hier Verschattung von Dächern)Screenshot 4: Verschattung von Dächern kann dazu führen, dass das Dach teilweise als „Grün“ interpretiert wirdScreenshot 5: Gefahr der Fehlinterpretation durch vertrocknete pflanzliche Strukturen (hier vertrocknete Rasenfläche)Screenshot 6: Die vertrocknete Rasenfläche kann dazu führen, dass sie teilweise als „versiegelt“ interpretiert wird
Danke für den fachlichen Input und das Coaching von M. Sc. Matthias Henning von der Hochschule Anhalt. So muss Netzwerken! Hier noch ein paar wichtige Bemerkungen und Ergänzungen von Matthias bzgl. der Grenzen und Gefahren bei Fehlinterpretation:
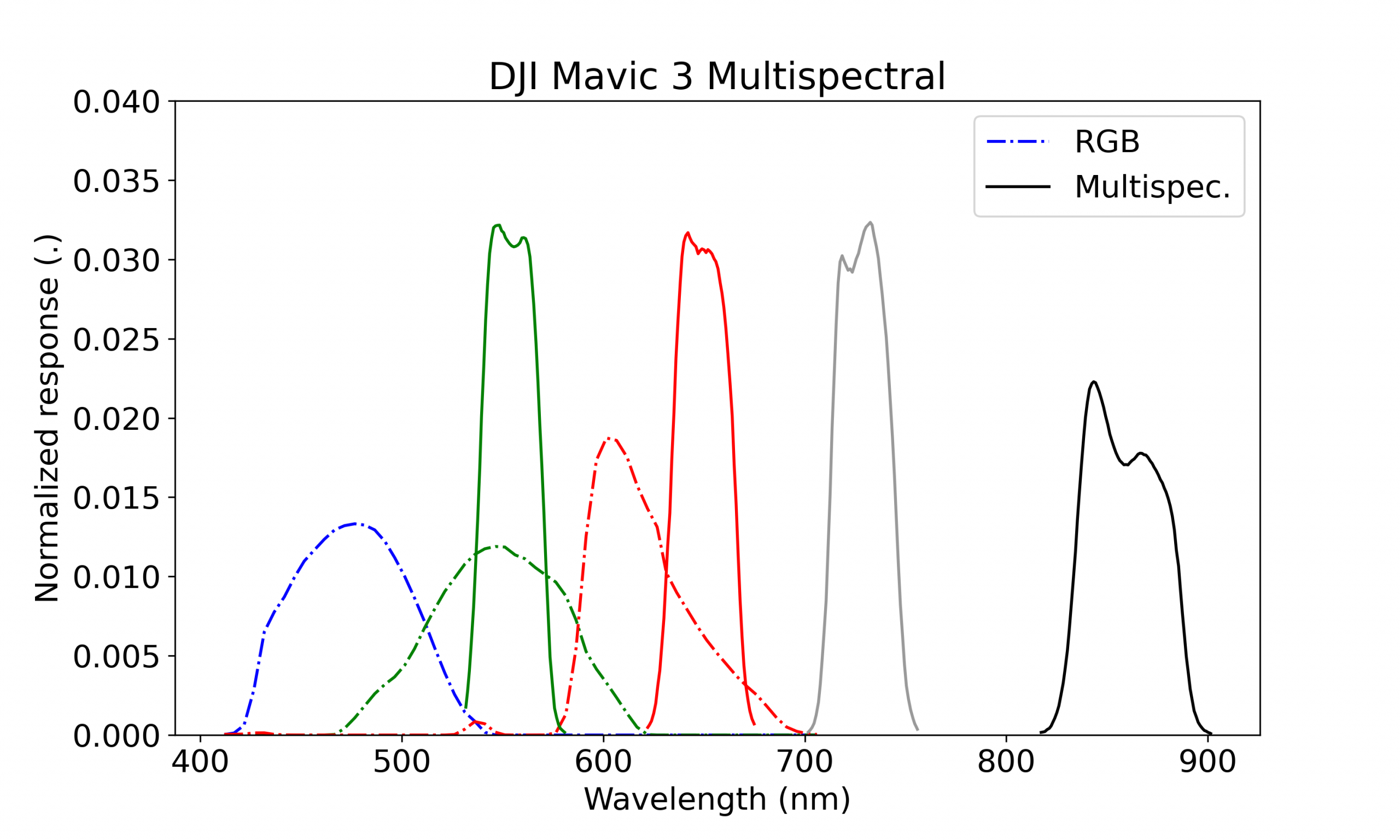
„So gerne und häufig der NDVI auch eingesetzt wird, sollten die Grenzen der jeweiligen Methode immer berücksichtigt werden. Beim NDVI sind diese vor allem bei den Sensoren (Kamera) und den aufgenommenen Lichtspektren zu finden. Einfache Kameras nehmen den NIR-Bereich lediglich als den Bereich wahr, der auf den roten Bereich folgt. Die Intensität der Lichtaufnahme ist bei jedem Kamerasensor unterschiedlich und gleicht einer Kurve. Etwas hochwertigere Kameras steuern die auf den Sensor treffenden Wellenlängenbereiche über einzelne schmalbandigere Filter. Im Bild unten sind die Bereiche der Multispektralkamera der im Einstiegs-UAV-Bereich häufig verwendeten DJI Mavic 3 zu sehen (CC-BY-4.0, Jon Atherton). Diese ordnet die Bereiche des roten und nah-infraroten Spektrums deutlich schmaler zu als z.B. den Rotbereich einer RGB-Kamera. Im Bereich der professionellen Fernerkundung werden diese Wellenlängenbereiche noch viel detaillierter und feiner erfasst. Daher können die NDVI-Werte unterschiedlicher Kamerasysteme nicht ohne weiteres verglichen werden. Ebenso spielen der Sonnenstand, Schattenwürfe, Zentrum der Bildaufnahme, Wuchsrhytmus der Pflanzen, Feuchtigkeit, die Temperaturen und atmosphärische Verzerrungen eine Rolle. Das Licht der Sonne musste immerhin bereits viele Kilometer durch die Atmosphäre zurücklegen, bevor es reflektiert wurde und zum Sensor gelangte. Selbst der Vergleich zweier Aufnahmen desselben Sensors ist daher nicht immer einfach, zumal jedes Sensorsystem teilweise eigene Korrekturen dafür vorsieht. Entweder wird daher der NDVI in jeder Aufnahme kalibriert, indem beispielsweise auf die Werte des vitalsten Baumes normalisiert wird. Oder aber es wird nicht der NDVI, sondern dessen Klassifikation je Aufnahme in verschiedene Vitalitätsklassen, miteinander verglichen.“
Bildquelle: Atherton, J., Alonso Chorda, L., Suomalainen, J., Miettinen, I., Kuurasuo, J., & Hakala, T. (2024). DJI Mavic 3 Multispectral Edition spectral response [Data set]. Zenodo. [3]
Neben NDVI findet Ihr weitere Indizes in folgendem Tweet [4] und der Index DataBase [5].
NDVI, EVI & SAVI are powerful tools in remote sensing, offering insights into vegetation health, density, & distribution.
This infographic highlights their differences in formula, sensitivity, strengths, weaknesses, computational requirements, and ideal use cases. pic.twitter.com/d5lqSjcx1t
Zum Wochenende meine Leseempfehlung. Einen wunderbaren Artikel über Flächenberechnung in GI-Systemen habe ich die Tage auf LinkedIn [1] gefunden. Im Artikel „Why your GIS polygons might be lying to you: The Zero-Area Paradox“ [2] zeigt Ahmad Zaenun Faiz, wie ein GIS die Flächeninhalte ermittelt und welche Besonderheiten und Fallen es dabei gibt. Selbstüberschneidene Polygone (self-intersecting polygons) haben danach „selbstverständlich“ eine falschen Flächeninhalt. Ich habe das Ganze mal im QGIS nachgestellt, siehe die folgende Animation. Übrigens, mein QGIS-Plugin QuickPolygonRepair [3] repariert via GEOS-Methode solche Polygone ;.)
Annimation: Falschen Flächeninhalt, nämlich 0,00 m² bei einem selbstüberschneidenen Polygon
Abbildung: Die alte und die neue Welt (Bildquellen [2], [3])
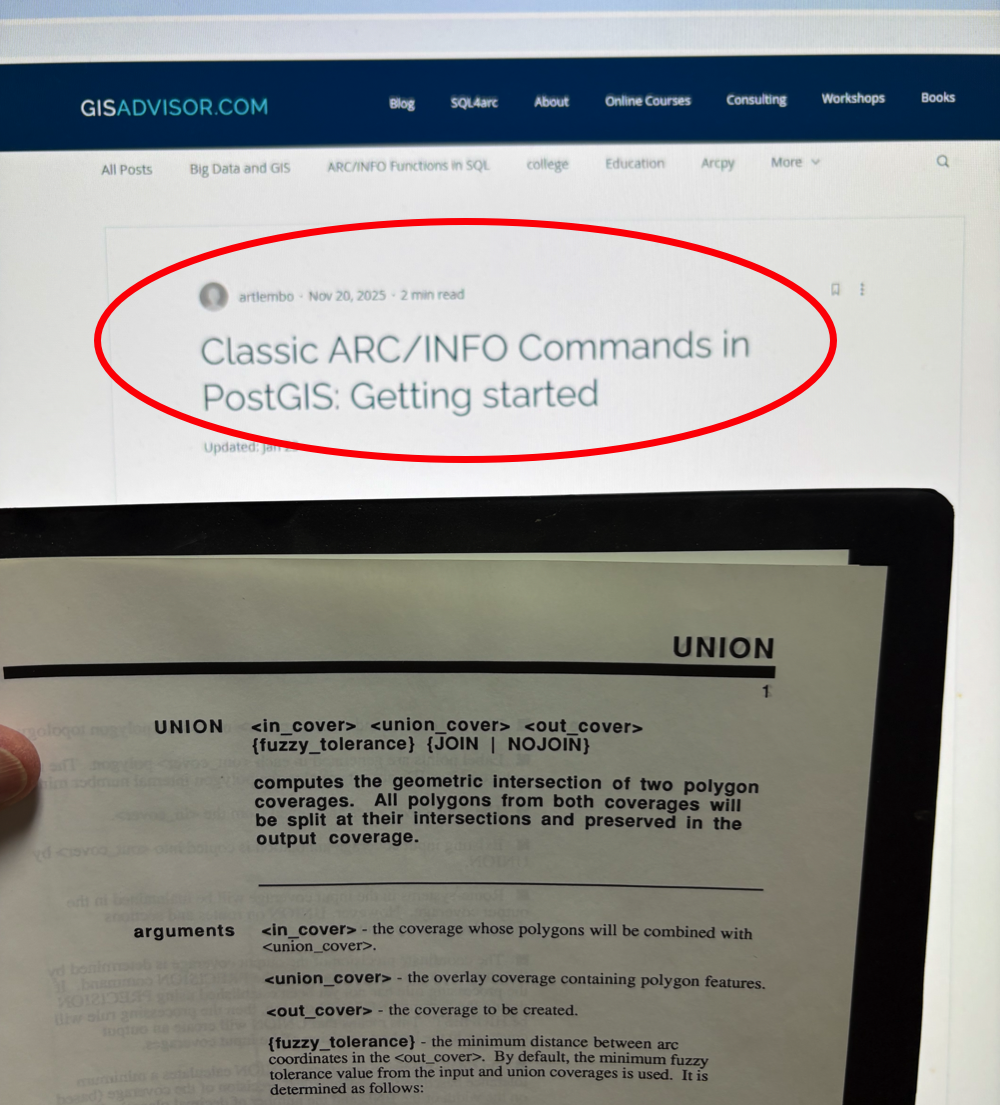
Seit 1991 arbeite ich mit GI-Systemen, angefangen habe ich mit ARC/INFO 4.0. Und damals, als Topologie noch eine heilige Kuh war, hatten wir leistungsstarke Funktionen für die Topologiebildung und das Geoprozessing. CLEAN & BUILD dienten der Qualitätssicherung und der korrekten Topologie, sie waren nach jeder Editiersitzung Pflicht. UNION, IDENTITY, CLIP, ERASE und Co. wurden für das Geoprozessing genutzt. Leider wurden später in der Geodatenwelt die Pflicht zur Topologie und auch diese einfachen und nützlichen Kommandozeile-Befehle aufgegeben. Ich jedenfalls hab sie mir immer mal wieder gewünscht.
Befragt man eine KI zum Thema „Indizierung von Datenbanken“, bekommt man z. B. folgende Antwort:
„Datenbankindizierung beschleunigt Suchanfragen durch das Erstellen von separaten Datenstrukturen (Indizes), die wie ein Inhaltsverzeichnis funktionieren und schnellen Zugriff auf bestimmte Datensätze ermöglichen, indem sie die Notwendigkeit des sequenziellen Durchsuchens großer Tabellen reduzieren; dies erhöht die Performance bei Suchen, erfordert aber zusätzlichen Speicher und Pflege bei Schreibvorgängen (INSERT, UPDATE, DELETE).“ [hier Google-KI-Antwort vom 26.01.2026, 20:00 Uhr]
Aber wusstet Ihr, wie viele verschiedene Arten der Indizierung in einer PostgreSQL möglich sind? Mir waren in meiner Praxis bisher im Wesentlichen nur B-Tree und speziell für Geodaten der GIST unter gekommen. Aber es gibt deutlich mehr. Durch einen LinkedIn-Beitrag [1] und einen Tweet [2] von Crunchy Data bin ich angepingt worden, dort kommen sie auf 10 verschiedene Arten von Indizes, andere Quellen [3] weisen 9 Typen aus.