Heute wieder mal ein Gastbeitrag, diesmal von meinem Fachkollegen Clemens Schenke-Hildebrandt, Geograph, GIS-Consultant und passionierter Rennradfahrer. Danke Clemens!
Wenn eine Karte mehr als eine Karte ist
Beim Fahrradverein Veloclub Asphaltrauschen e.V. (VCA) tragen die Vereinsmitglieder ein Trikot, auf dem Linien und Höhen zu erkennen sind, die eine abstrakte Landschaft auf einer Karte zu bilden scheinen. Dabei handelt es sich aber nicht um einen Stadtplan von Halle (Saale), sondern einen Joyplot der Saalestadt. Wer Halle kennt, erkennt darin nicht sofort jede Straße, aber etwas anderes Markantes: die Saaleaue, die Hochflächen, die Kanten der Stadt – das Gefühl eines Ortes.

Für mich ist dieses Trikot deshalb ein guter Einstieg in die Geschichte von Geodaten beim VCA.
Die Grafik, der Joyplot, war nicht als klassischer Vereinsaufdruck gedacht. Sie war der Versuch, Halle aus Daten heraus sichtbar zu machen und daraus ein Motiv zu entwickeln, das zum Verein passt und die tiefe Verbundenheit zur Saalestadt widerspiegelt. Die Fahrrad-Community bewegt sich ständig durch die Stadt und das Umland. Warum sollte ihre visuelle Sprache dann nicht aus genau diesem Raum entstehen?
Die ausführlichere Geschichte zum Trikotmotiv steht auf asphaltrauschen.cc: „Unknown Places“ – das Veloclub Asphaltrauschen Trikot. Die Höheninformationen für den Joyplot stammen aus dem Digitalen Geländemodell DGM11 Sachsen-Anhalt.
Angefangen hat diese Verbindung aber einfacher.
Im ersten Corona-Jahr fehlte der lokalen Fahrrad-Community das, was sonst fast selbstverständlich war: gemeinsame Ausfahrten, Training, Treffen, Events und kleine Wettkämpfe. Aus dieser Lücke entstand mit dem Spring Break ein Event mit einer einfachen Idee: Strava-Segmente2 wurden zu kleinen Etappen und jede Woche kam eine neue Herausforderung dazu. Die Ergebnisse wurden manuell zusammengetragen.
Aus heutiger Sicht war das technisch noch ziemlich bodenständig. Keine Datenbank, keine API-Automatisierung, keine große Webanwendung. Ich kopierte Ranglisten aus Strava, pflegte Ergebnisse in Excel und baute eine einfache Übersichtskarte. Aber genau dort begann etwas, das später wichtig wurde: Bewegungsdaten waren nicht nur private Trainingsaufzeichnungen, sie wurden zu Material für ein gemeinsames Spiel.
Der nächste größere Schritt war ein Alleycat.
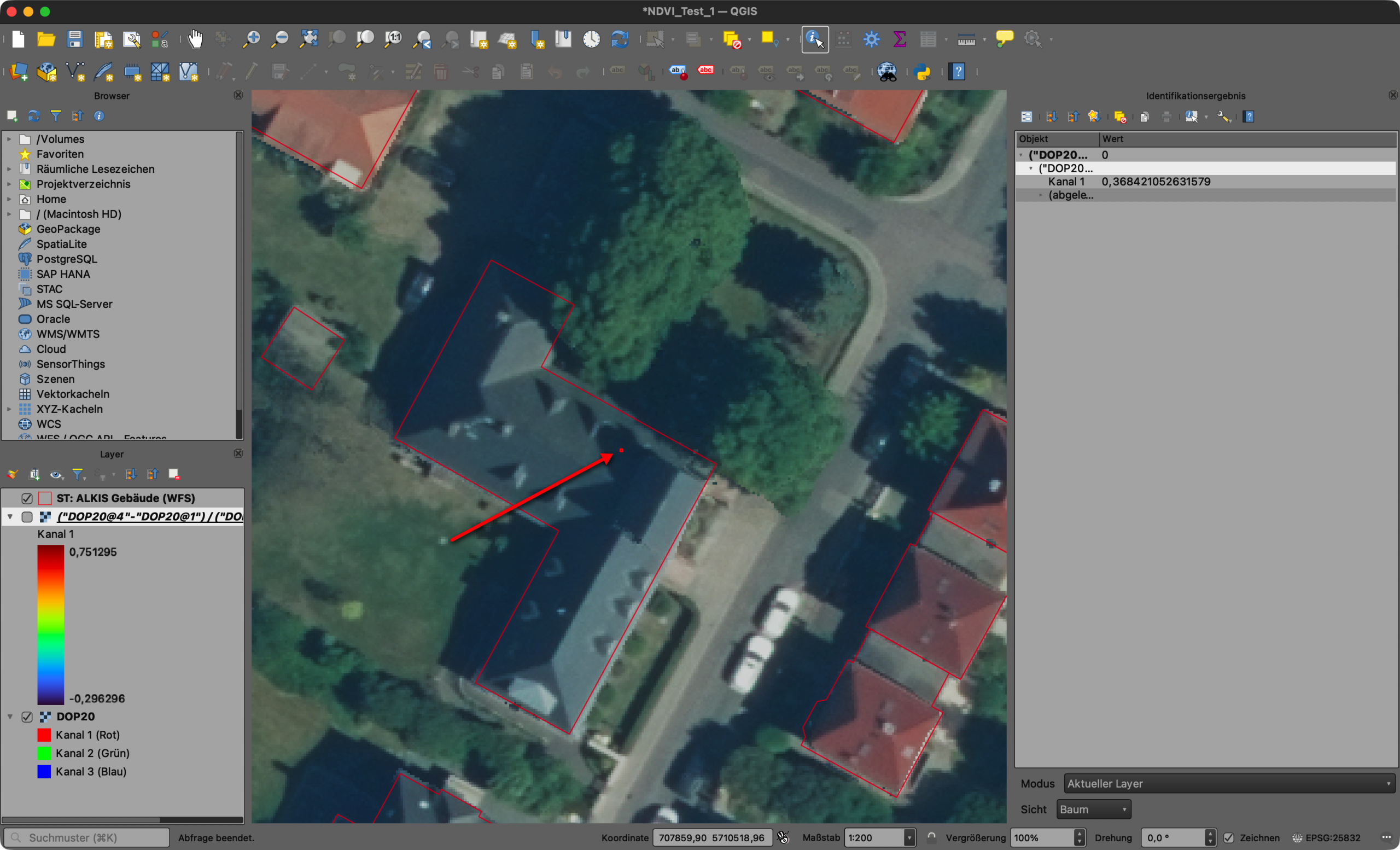
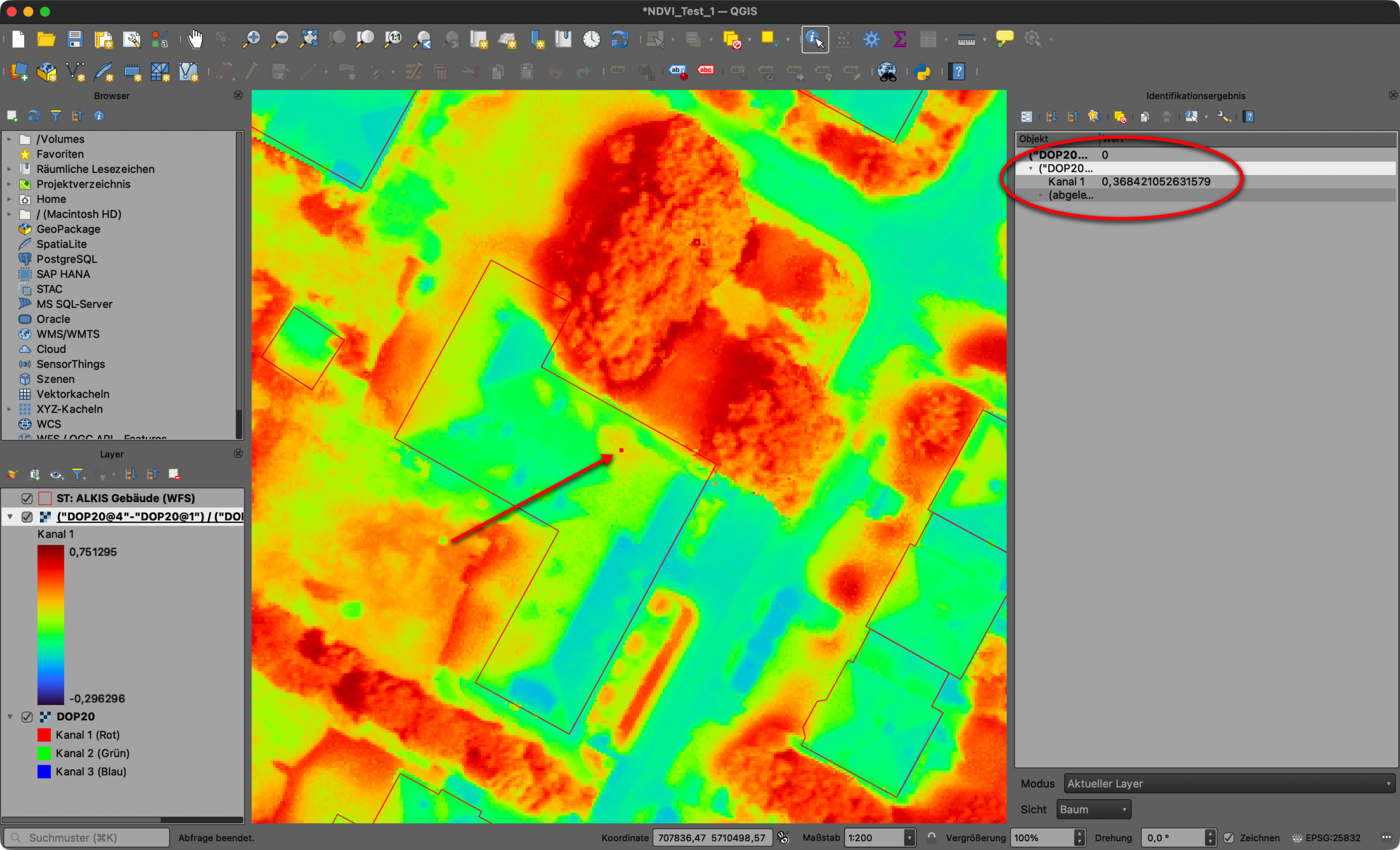
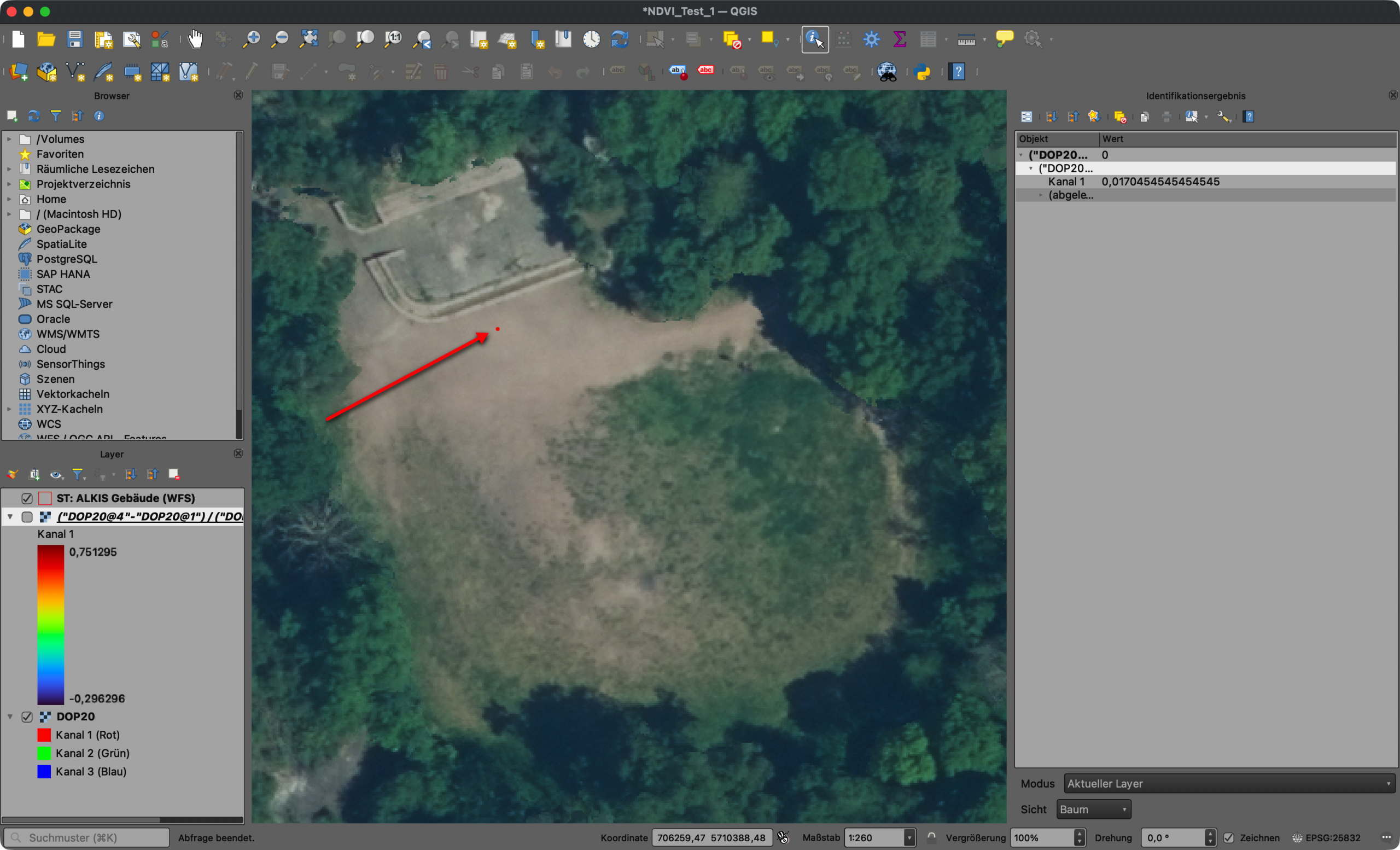
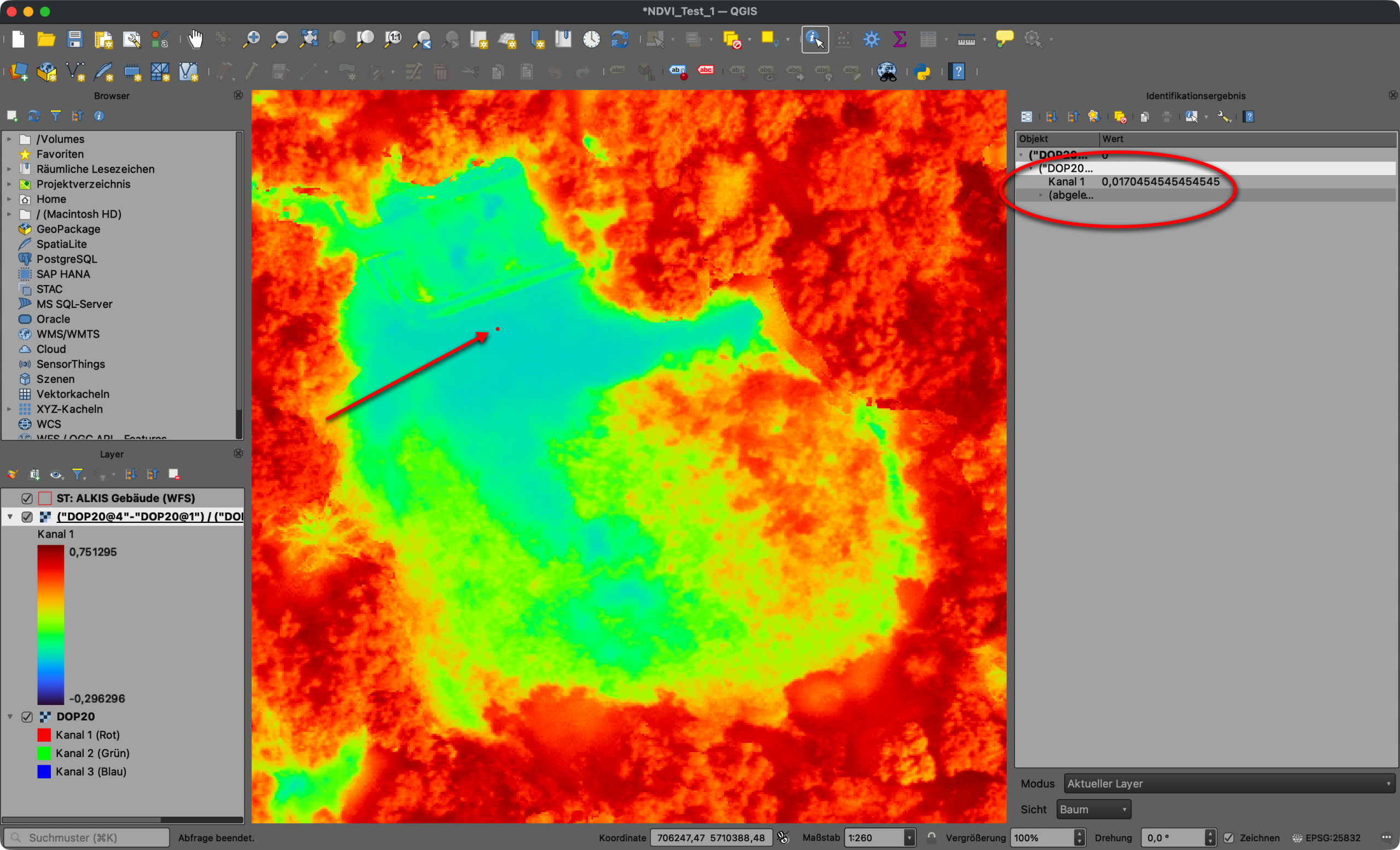
Das klassische Alleycat kommt aus der Fahrradkurierkultur: Checkpoints, Orientierung, Tempo, eigene Routenwahl – vergleichbar mit einer Schnitzeljagd. Für unseren Kontext wurde daraus ein kontaktloses 24-Stunden-Rennen, bei dem Städte, Orte und markante Punkte zu Checkpoints wurden. OpenStreetMap lieferte die Grundlage. Um diese Checkpoints wurden unterschiedliche Radien definiert und wer mit seinem GPX-Track durch diese Bereiche fuhr, sammelte Punkte.
Das war für mich der erste Augenblick, in dem GIS beim VCA nicht mehr nur eine begleitende Karte war, sondern wesentlicher Teil der Spielmechanik wurde.
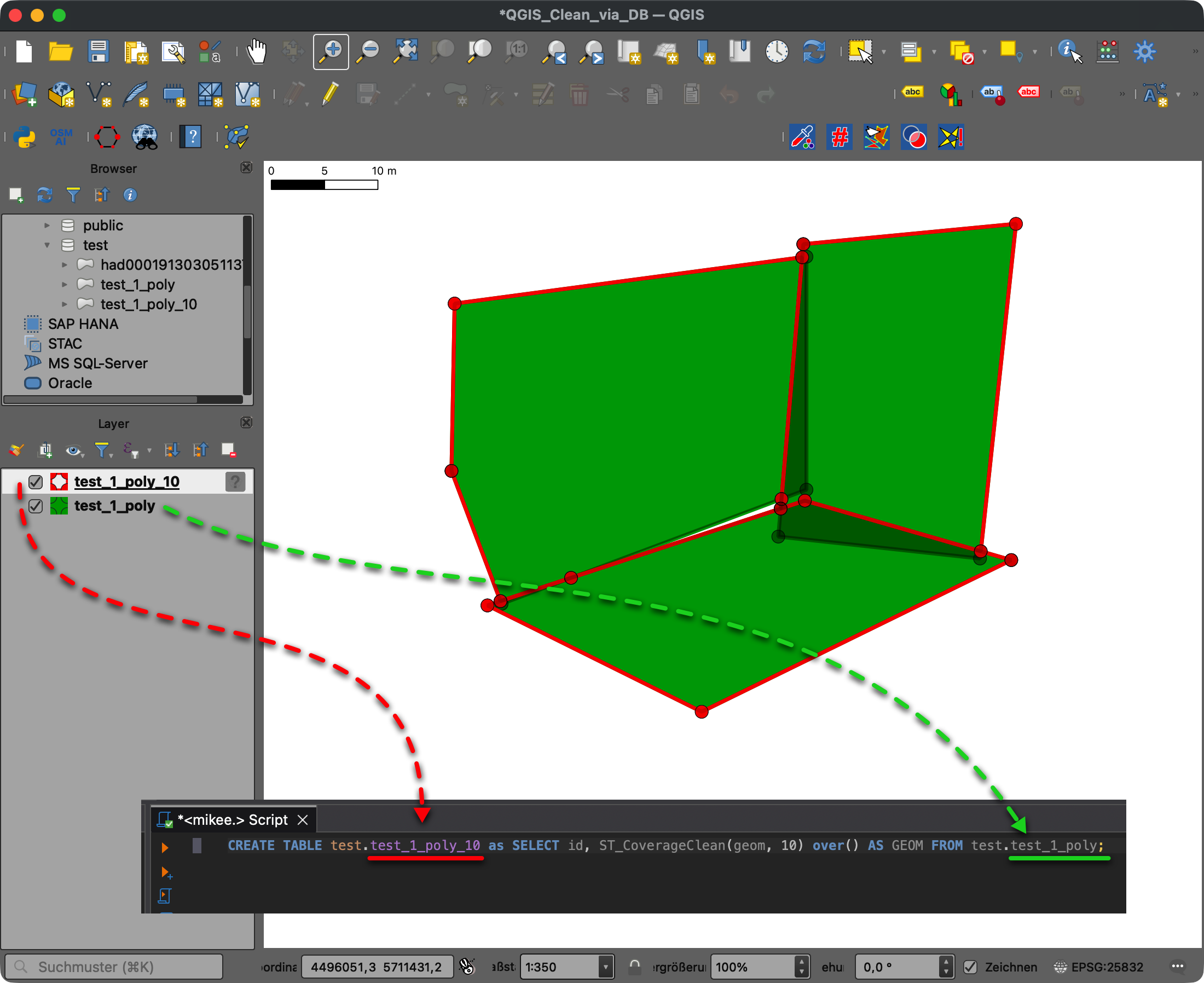
Die Auswertung lief damals noch in QGIS: Checkpoints puffern, GPX-Tracks schneiden, Treffer prüfen, Punkte zusammenrechnen. Ein gutes Bild dafür ist ein Screenshot aus dem QGIS Model Builder: GPX-Dateien und Checkpoints laufen dort als einzelne Verarbeitungsschritte zusammen. Für mich fühlte sich das damals wie Magie an, weil nicht mehr jeder Schritt einzeln nacheinander angeklickt werden musste, sondern der Ablauf als Modell sichtbar und wiederholbar wurde.
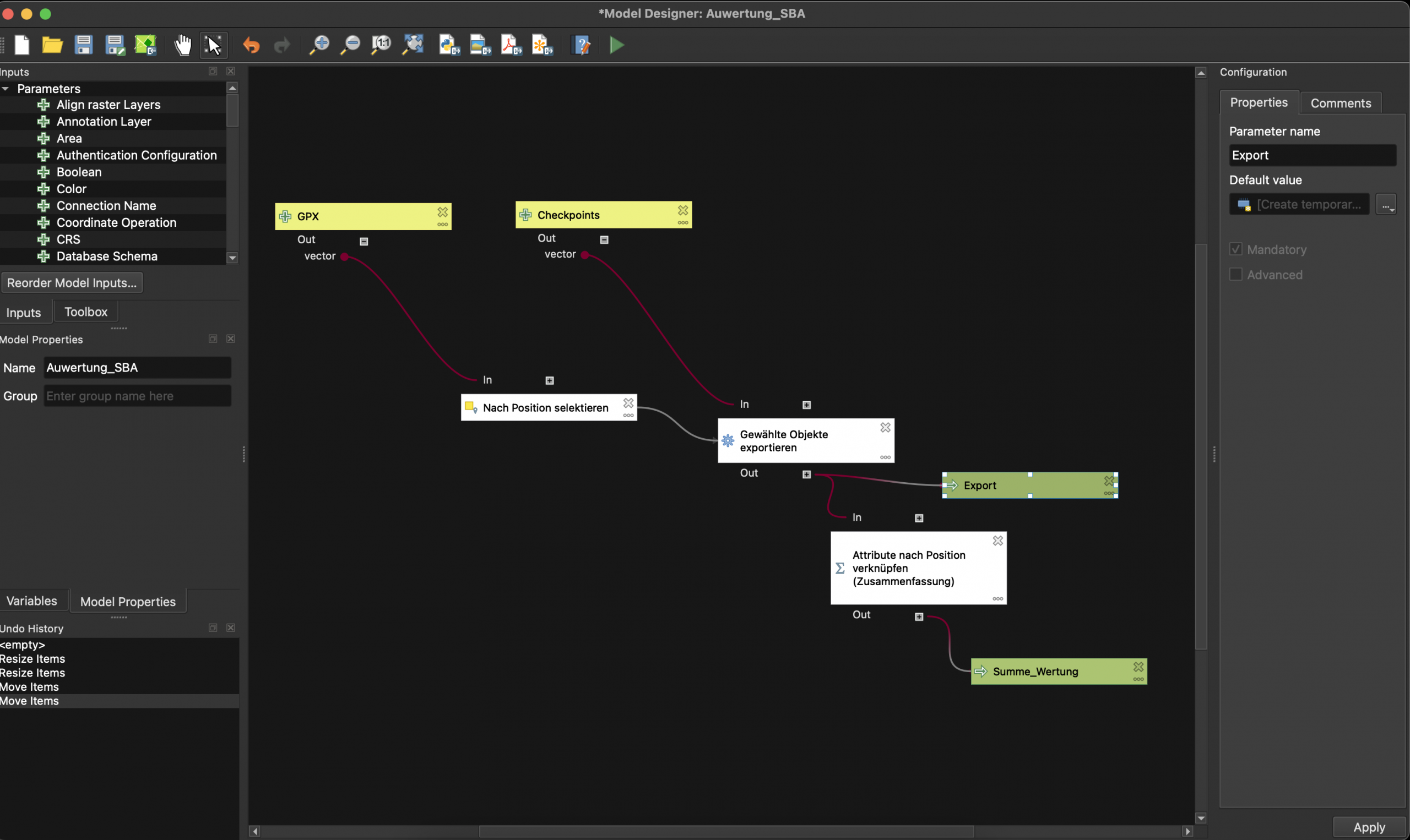
Nichts davon war als großes Produkt gebaut. Aber es zeigte, wie stark sich Radfahren, offene Geodaten und einfache räumliche Regeln verbinden lassen. Der Joyplot von Halle kam später aus einer anderen Richtung. Nicht mehr: Wer fährt wo entlang? Sondern: Wie kann eine Stadt als Datenbild aussehen?
Ein Joyplot besteht aus vielen versetzten Profilen und für Halle bedeutete das: Höhendaten abtasten, Linien erzeugen, die Topografie abstrahieren. So wurden die Saaleaue, die nördlichen Felskanten, die Dölauer Heide und die Hochflächen der Stadt nicht als exakte Karte gezeigt, sondern als Rhythmus.
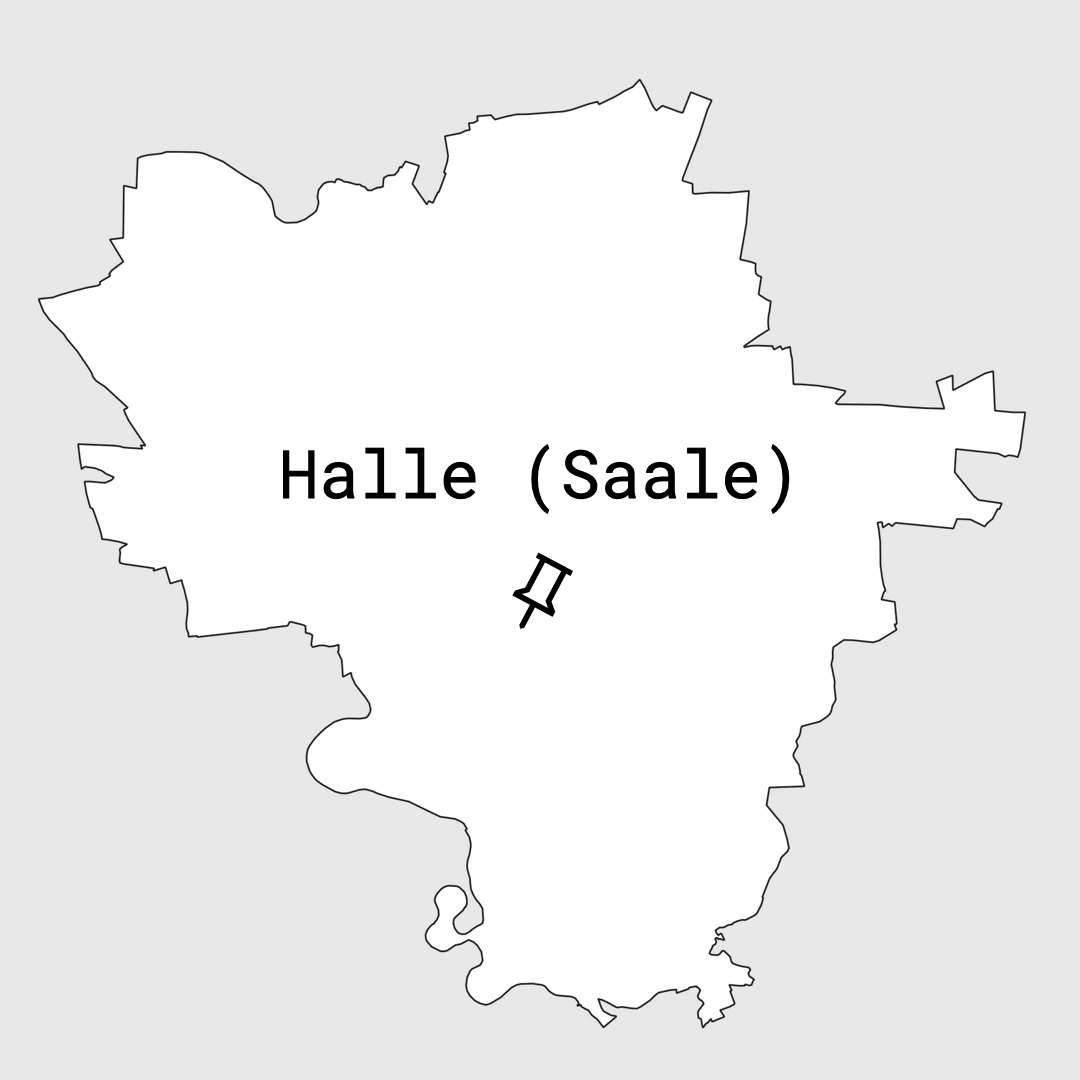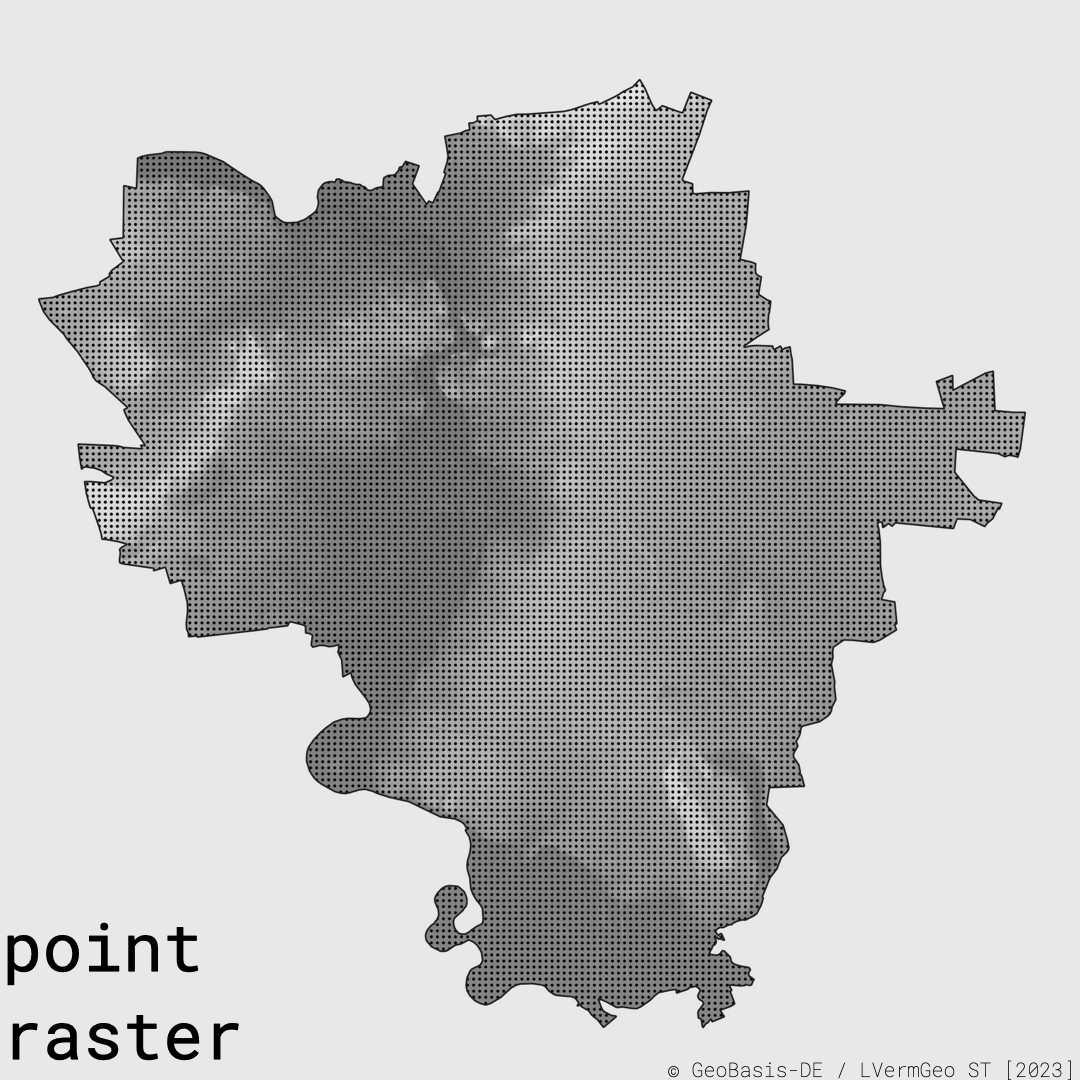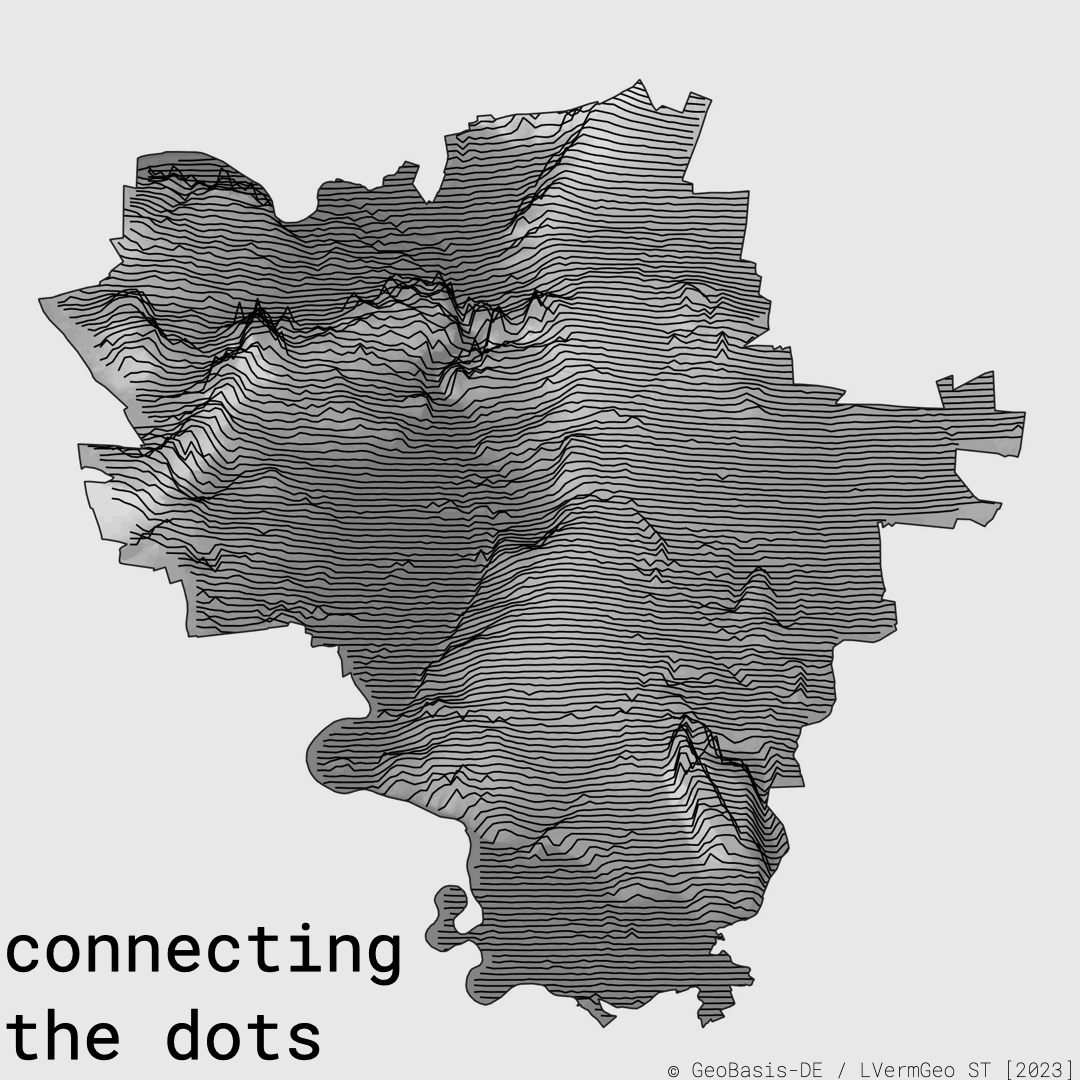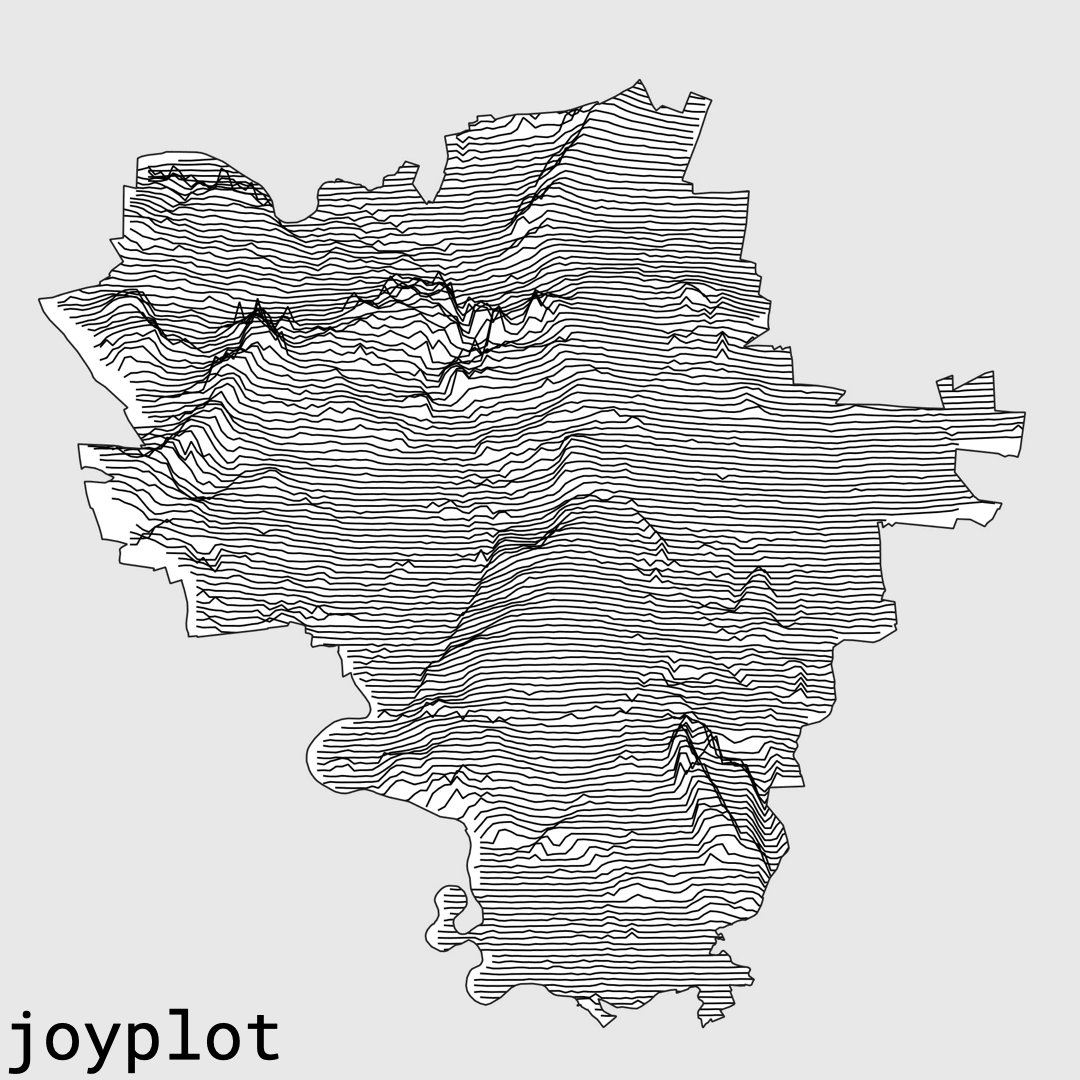
Als daraus die Idee für ein Trikotmotiv entstand, veränderte sich die Rolle der Geodaten noch einmal: Sie waren nicht mehr nur Werkzeug für Auswertung oder Orientierung, sie wurden Teil einer Vereinsidentität.
Diese Entwicklung finde ich bis heute spannend.
Geodaten wirken durch Koordinaten, Layer, Projektionen, Attribute und Formate oft technisch. Im Alltag eines Fahrradvereins zählt aber etwas Anderes: In der Nutzung muss eine Karte nicht nur korrekt, sie muss anschlussfähig sein. Sie muss einen Anlass tragen können, eine Ausfahrt erklären, eine Erinnerung festhalten oder ein Gefühl für einen Ort transportieren.
Beim VCA ist daraus nach und nach ein kleiner Werkzeugkasten entstanden.
Mal geht es um Strava-Segmente und Rankings, dann um Checkpoints und GPX-Tracks oder um Höhendaten, OSM-Daten oder reduzierte Routengrafiken. Später kamen Python, eigene Skripte und automatisierte Workflows dazu. Aber der Ausgangspunkt war nicht Technik um der Technik willen. Der Ausgangspunkt war immer eine konkrete Frage aus der Community:
- Wie halten wir Verbindung, wenn wir nicht gemeinsam fahren können?
- Wie machen wir aus einer Route ein Spiel?
- Wie macht man eine Stadt zur Vereinsidentität, zu einem Trikotmotiv?
- Wie zeigen wir, was unsere Ausfahrten unterscheidet?
- Genau an dieser Stelle treffen sich für mich Radkultur und GIS.
Geodaten sind beim Veloclub Asphaltrauschen keine neutrale Hintergrundkarte. Sie sind ein Mittel, um Bewegung, Ort, Gemeinschaft und Gestaltung zusammenzubringen.
Aus diesem Werkzeugkasten sind später vier sehr unterschiedliche Kartenlinien entstanden: Social Ride, FLINTA*-Ride, Schotterbande und Temporunde. Jede dieser Runden hat ihren eigenen Charakter, und jede Karte versucht, diesen Charakter sichtbar zu machen. Aber das ist eigentlich schon die nächste Geschichte.

Zum Autor:
Clemens Schenke-Hildebrandt ist Geograph, GIS-Consultant und Product Owner mit Schwerpunkt auf Geodaten, WebGIS, Kartenanwendungen und produktnaher Softwareentwicklung. Beim VCA verbindet er Radkultur, Community-Projekte und Geodatenarbeit, unter anderem in Karten, Visualisierungen und GPS-basierten Challenges.
Kontakt: https://linktr.ee/clemensschenke
- DGM1 steht für Digitales Geländemodell mit einer Rasterweite von 1 m. Für Sachsen-Anhalt stellt das Landesamt für Vermessung und Geoinformation Sachsen-Anhalt das DGM1 kostenfrei bereit: https://www.lvermgeo.sachsen-anhalt.de/de/gdp-dgm1.html. ↩︎
- Ein Strava-Segment ist ein festgelegter Abschnitt auf einer Straße, einem Weg oder einer Strecke, für den Strava automatisch Zeiten aus aufgezeichneten Aktivitäten vergleicht. Wer eine Fahrt oder einen Lauf hochlädt und durch dieses Segment kommt, erscheint mit der eigenen Zeit in einer Rangliste. Für den Spring Break konnten solche Segmente deshalb wie digitale Etappen genutzt werden: Die Strecke war klar definiert, die Zeitmessung kam aus den GPS-Aufzeichnungen, und die Ergebnisse mussten anschließend nur noch ausgewertet werden. ↩︎